Llistat de publicacions i treballs relacionats
2026
BSC's Submission to the Instruction Following Track of IWSLT 2026
Oriol Pareras, Joan Lladó, Pol Buitrago, Marc Casals-Salvador, Federico Costa and Cristina España-Bonet
In Proceedings of the 23rd International Conference on Spoken Language Translation (IWSLT 2026), pages 171-182, San Diego, USA. Association for Computational Linguistics, July 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
We present the Barcelona Supercomputing Center (BSC) submission to the Instruction Following (IF) track of IWSLT 2026, which evaluates unified spoken language systems capable of solving multiple tasks through natural language instructions. Our system consists of an end-to-end (E2E) architecture that combines a speech encoder with a translation-oriented Large Language Model. The model is trained on speech and text data, covering automatic speech recognition, translation, question answering, and instruction following. We investigate a Chain-of-Thought (CoT) generation strategy that explicitly decomposes tasks by producing an intermediate transcription before the final output, which enables effective reuse of text-only supervision and improves robustness across tasks. To further support generalization, we design diverse prompt formulations and align text-only and speech inputs under a shared inference pattern. Results on IWSLT 2025 evaluation data show that our approach achieves competitive and even state-of-the-art performance across tasks.
@inproceedings{pareras-etal-2026-bscs,
title = {BSC's Submission to the Instruction Following Track of IWSLT 2026},
author = {Pareras, Oriol and Llad\'o, Joan and Buitrago, Pol and Casals-Salvador, Marc and Costa, Federico and Espa{\~n}a-Bonet, Cristina},
editor = {Salesky, Elizabeth and Anastasopoulos, Antonios and Negri, Matteo and Federico, Marcello},
booktitle = {Proceedings of the 23rd International Conference on Spoken Language Translation (IWSLT 2026)},
month = jul,
year = {2026},
address = {San Diego, USA},
publisher = {Association for Computational Linguistics},
url = {https://aclanthology.org/2026.iwslt-1.19/},
doi = {10.18653/v1/2026.iwslt-1.19},
pages = {171--182},
ISBN = {979-8-89176-411-8}
}
DFKI-MLT at SemEval-2026 Task 7: Steering Multilingual Models Towards Cultural Knowledge
Yusser Al Ghussin, Daniil Gurgurov, Yasser Hamidullah, Josef van Genabith, Cristina España-Bonet and Simon Ostermann
In Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), pages 2548-2563, San Diego, USA. Association for Computational Linguistics, July 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Large language models (LLMs) are increasingly used across diverse linguistic and cultural contexts, yet their cultural knowledge remains uneven across regions and languages. We present the DFKI-MLT system for SemEval-2026 Task 7 on cultural awareness, where we apply activation steering to multilingual LLMs using language vectors extracted from parallel FLORES data. Our method performs inference-time adaptation by adding language-specific steering vectors to the residual stream at a selected transformer layer, without any parameter updates. We participated in both the short-answer (SAQ) and multiple-choice (MCQ) tracks; however, only our MCQ submission received an official score. In the official MCQ track, we achieved 86.96% accuracy, ranking 7th out of 17 teams. To better understand system behavior, we conduct post-hoc analyses on the shared-task MCQ and SAQ settings. These analyses show that activation steering yields modest and heterogeneous improvements on cultural reasoning: gains are strongly layer-sensitive, vary substantially across language-region pairs (some configurations even degrade performance), and interact with prompt formulation (generic vs. culturally conditioned prompts). Our findings suggest that prompt design and activation steering should be jointly optimized for culturally aware multilingual inference. We release our code and experimental configurations at https://github.com/Yusser96/SemEval-2026-Track7.
@inproceedings{al-ghussin-etal-2026-dfki,
title = {DFKI-MLT at SemEval-2026 Task 7: Steering Multilingual Models Towards Cultural Knowledge},
author = {Al Ghussin, Yusser and Gurgurov, Daniil and Hamidullah, Yasser and van Genabith, Josef and Espa{\~n}a-Bonet, Cristina and Ostermann, Simon},
editor = {Kochmar, Ekaterina and Ghosh, Debanjan and North, Kai and Komachi, Mamoru},
booktitle = {Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026)},
month = jul,
year = {2026},
address = {San Diego, USA},
publisher = {Association for Computational Linguistics},
url = {https://aclanthology.org/2026.semeval-1.322/},
doi = {10.18653/v1/2026.semeval-1.322},
pages = {2548--2563},
ISBN = {979-8-89176-414-9}
}
Grounding or Guessing? Visual Signals for Detecting Hallucinations in Sign Language Translation
Yasser Hamidullah, Koel Dutta Chowdhury, Yusser Al Ghussin, Shakib Yazdani, Cennet Oguz, Josef van Genabith and Cristina España-Bonet
In Proceedings of the Fourteenth International Conference on Learning Representations (ICLR 2026), Rio de Janeiro, Brazil. April 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Hallucination, where models generate fluent text unsupported by visual evidence, remains a major flaw in vision-language models and is particularly critical in sign language translation (SLT). In SLT, meaning depends on precise grounding in video, and gloss-free models are especially vulnerable because they map continuous signer movements directly into natural language without intermediate gloss supervision that serves as alignment. We argue that hallucinations arise when models rely on language priors rather than visual input. To capture this, we propose a token-level reliability measure that quantifies how much the decoder uses visual information. Our method combines feature-based sensitivity, which measures internal changes when video is masked, with counterfactual signals, which capture probability differences between clean and altered video inputs. These signals are aggregated into a sentence-level reliability score, providing a compact and interpretable measure of visual grounding. We evaluate the proposed measure on two SLT benchmarks (PHOENIX-2014T and CSL-Daily) with both gloss-based and gloss-free models. Our results show that reliability predicts hallucination rates, generalizes across datasets and architectures, and decreases under visual degradations. Beyond these quantitative trends, we also find that reliability distinguishes grounded tokens from guessed ones, allowing risk estimation without references; when combined with text-based signals (confidence, perplexity, or entropy), it further improves hallucination risk estimation. Qualitative analysis highlights why gloss-free models are more susceptible to hallucinations. Taken together, our findings establish reliability as a practical and reusable tool for diagnosing hallucinations in SLT, and lay the groundwork for more robust hallucination detection in multimodal generation.
@inproceedings{hamidullah2026grounding,
title = {Grounding or Guessing? Visual Signals for Detecting Hallucinations in Sign Language Translation},
author = {Yasser Hamidullah and Koel Dutta Chowdhury and Yusser Al Ghussin and Shakib Yazdani and Cennet Oguz and Josef van Genabith and Cristina Espa{\~n}a-Bonet},
booktitle = {The Fourteenth International Conference on Learning Representations},
month = apr,
year = {2026},
address = {Rio de Janeiro, Brazil},
url = {https://openreview.net/forum?id=bLFW2T3UHq}
}
A Critical Study of Automatic Evaluation in Sign Language Translation
Shakib Yazdani, Yasser Hamidullah, Cristina España-Bonet, Eleftherios Avramidis and Josef van Genabith
In Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), pages 9535-9548, Palma, Mallorca, Spain. European Language Resources Association (ELRA), May 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Automatic evaluation metrics are crucial for advancing sign language translation (SLT). Current SLT evaluation metrics, such as BLEU and ROUGE, are only text-based, and it remains unclear to what extent text-based metrics can reliably capture the quality of SLT outputs. To address this gap, we investigate the limitations of text-based SLT evaluation metrics by analyzing six metrics, including BLEU, chrF, and ROUGE, as well as BLEURT on the one hand, and large language model (LLM)-based evaluators such as G-Eval and GEMBA zero-shot direct assessment on the other hand. Specifically, we assess the consistency and robustness of these metrics under three controlled conditions: paraphrasing, hallucinations in model outputs, and variations in sentence length. Our analysis highlights the limitations of lexical overlap metrics and demonstrates that while LLM-based evaluators better capture semantic equivalence often missed by conventional metrics, they can also exhibit bias toward LLM-paraphrased translations. Moreover, although all metrics are able to detect hallucinations, BLEU tends to be overly sensitive, whereas BLEURT and LLM-based evaluators are comparatively lenient toward subtle cases. This motivates the need for multimodal evaluation frameworks that extend beyond text-based metrics to enable a more holistic assessment of SLT outputs.
@inproceedings{yazdani-etal-2026-critical,
title = {A Critical Study of Automatic Evaluation in Sign Language Translation},
author = {Yazdani, Shakib and Hamidullah, Yasser and Espa{\~n}a-Bonet, Cristina and Avramidis, Eleftherios and van Genabith, Josef},
booktitle = {Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026)},
month = may,
year = {2026},
pages = {9535--9548},
address = {Palma, Mallorca, Spain},
publisher = {European Language Resources Association (ELRA)},
editor = {Piperidis, Stelios and Bel, N\'uria and van den Heuvel, Henk and Ide, Nancy and Krek, Simon and Toral, Antonio},
doi = {10.63317/4n2sooe4fb2i}
}
KinyCOMET: Automatic Evaluation of Machine Translation Systems for Kinyarwanda-English
Prince Chris Mazimpaka, Jan Nehring, Samuel Rutunda and Cristina España-Bonet
In Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), pages 4881-4888, Palma, Mallorca, Spain. European Language Resources Association (ELRA), May 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
This paper presents KinyCOMET, a new automatic evaluation metric for Kinyarwanda-English machine translation (MT). Current MT evaluation in Rwanda relies mainly on BLEU and chrF, which have been shown to correlate poorly with human judgments. To address this gap, we created a Direct Assessment (DA) dataset for Kinyarwanda-English translations and used it to fine-tune COMET models for this language pair. We evaluate two variants: KinyCOMET XLM-RoBERTa, trained from a multilingual encoder without Kinyarwanda data, and KinyCOMET Unbabel, a fine-tuned version of the Unbabel COMET model. Both models achieve strong correlations with human evaluations, with KinyCOMET Unbabel outperforming all baselines, including AfriCOMET, chrF, and BLEU. Our results show that fine-tuning pre-trained multilingual models can yield high-quality evaluators even for low-resource languages that the base model was not trained on. We release both the models and the annotated dataset publicly to foster further research on African language evaluation.
@inproceedings{mazimpaka-etal-2026-kinycomet,
title = {KinyCOMET: Automatic Evaluation of Machine Translation Systems for Kinyarwanda-English},
author = {Mazimpaka, Prince Chris and Nehring, Jan and Rutunda, Samuel and Espa{\~n}a-Bonet, Cristina},
booktitle = {Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026)},
month = may,
year = {2026},
pages = {4881--4888},
address = {Palma, Mallorca, Spain},
publisher = {European Language Resources Association (ELRA)},
editor = {Piperidis, Stelios and Bel, N\'uria and van den Heuvel, Henk and Ide, Nancy and Krek, Simon and Toral, Antonio},
doi = {10.63317/3nawgmkiq3mu}
}
PETra: A Multilingual Corpus of Pragmatic Explicitation in Translation
Doreen Osmelak, Koel Dutta Chowdhury, Uliana Sentsova, Cristina España-Bonet and Josef van Genabith
In Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), pages 8756-8766, Palma, Mallorca, Spain. European Language Resources Association (ELRA), May 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Translators often enrich texts with background details that make implicit cultural meanings explicit for new audiences. This phenomenon, known as pragmatic explicitation, has been widely discussed in translation theory but rarely modeled computationally. We introduce PETra, the first multilingual corpus and detection framework for pragmatic explicitation. The corpus consists of 2,900 sentence pairs from TED-Multi and Europarl, covers twelve language pairs, and includes additions such as entity descriptions, measurement conversions, and translator remarks. We identify candidates through null alignments and refine them using active learning with human annotation. Our results show that entity and system-level (e.g., metric conversions) explicitations are most frequent, and that active learning improves classifier accuracy by 7-8 percentage points, achieving up to 0.88 accuracy and 0.82 F1 for the best transfer languages. PETra establishes pragmatic explicitation as a measurable, cross-linguistic phenomenon and takes a step towards building culturally aware machine translation.
@inproceedings{osmelak-etal-2026-petra,
title = {PETra: A Multilingual Corpus of Pragmatic Explicitation in Translation},
author = {Doreen Osmelak and Koel Dutta Chowdhury and Uliana Sentsova and Cristina Espa{\~n}a-Bonet and Josef van Genabith},
editor = {Stelios Piperidis and N\'uria Bel and Henk van den Heuvel and Nancy Ide and Simon Krek and Antonio Toral},
url = {https://lrec.elra.info/lrec2026-main-689},
doi = {https://doi.org/10.63317/56tberz7nmwy},
year = {2026},
booktitle = {Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026)},
pages = {8756--8766},
publisher = {European Language Resources Association (ELRA)},
address = {Palma, Mallorca, Spain}
}
Revisiting Direct Speech-to-Text Translation with Speech LLMs: Better Scaling than CoT Prompting?
Oriol Pareras, Gerard I. Gállego, Federico Costa, Cristina España-Bonet and Javier Hernando
In Proceedings of ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 18407-18411, Barcelona, Spain. IEEE, May 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Recent work on Speech-to-Text Translation (S2TT) has focused on LLM-based models, introducing the increasingly adopted Chain-of-Thought (CoT) prompting, where the model is guided to first transcribe the speech and then translate it. CoT typically outperforms direct prompting primarily because it can exploit abundant Automatic Speech Recognition (ASR) and Text-to-Text Translation (T2TT) datasets to explicitly model its steps. In this paper, we systematically compare CoT and Direct prompting under increasing amounts of S2TT data. To this end, we pseudo-label an ASR corpus by translating its transcriptions into six European languages, and train LLM-based S2TT systems with both prompting strategies at different data scales. Our results show that Direct improves more consistently as the amount of data increases, suggesting that it may become a more effective approach as larger S2TT resources are created.
@inProceedings{parerasEtAl:ICASSP26,
author={Pareras, Oriol and G\'allego, Gerard I. and Costa, Federico and Espa{\~n}a-Bonet, Cristina and Hernando, Javier},
booktitle={ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Revisiting Direct Speech-to-Text Translation with Speech LLMs: Better Scaling than CoT Prompting?},
year={2026},
pages={18407--18411},
month = may,
year = "2026",
address = "Barcelona, Spain",
keywords={speech-to-text translation;speech large language models},
doi={10.1109/ICASSP55912.2026.11464161}
}
Zero-Shot TTS with Enhanced Audio Prompts: BSC Submission for the 2026 WildSpoof Challenge TTS Track
Jose Giraldo, Alex Peiró-Lilja, Rodolfo Zevallos and Cristina España-Bonet
In Proceedings of ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 21913-21915, Barcelona, Spain. IEEE, May 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
We evaluate two non-autoregressive architectures, StyleTTS2 and F5-TTS, to address the spontaneous nature of in-the-wild speech. Our models utilize flexible duration modeling to improve prosodic naturalness. To handle acoustic noise, we implement a multi-stage enhancement pipeline using the Sidon model, which significantly outperforms standard Demucs in signal quality. Experimental results show that finetuning enhanced audios yields superior robustness, achieving up to 4.21 UTMOS and 3.47 DNSMOS. Furthermore, we analyze the impact of reference prompt quality and length on zero-shot synthesis performance, demonstrating the effectiveness of our approach for realistic speech generation.
@inProceedings{giraldoEtAl:ICASSP2026,
author={Giraldo, Jose and Peir\'o-Lilja, Alex and Zevallos, Rodolfo and Espa{\~n}a-Bonet, Cristina},
booktitle={ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Zero-Shot TTS with Enhanced Audio Prompts: BSC Submission for the 2026 WildSpoof Challenge TTS Track},
year={2026},
pages={21913--21915},
month = may,
year = "2026",
address = "Barcelona, Spain",
keywords={Protocols;High frequency;HTTP;Radio frequency;Learning (artificial intelligence);Artificial intelligence;
Learning systems;Neural networks;Transfer learning;Speech to text;wildspoof challenge;text-to-speech;audio-prompt;zero-shot},
doi={10.1109/ICASSP55912.2026.11464250}
}
A Comprehensive Evaluation of Chain-of-Thought Faithfulness in Persian Classification Tasks
Shakib Yazdani, Cristina España-Bonet, Eleftherios Avramidis, Yasser Hamidullah and Josef van Genabith
In Proceedings of the Second Workshop on Language Models for Low-Resource Languages (LoResLM 2026), pages 311-323, Rabat, Morocco. Association for Computational Linguistics. March 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Large language models (LLMs) have shown remarkable performance when prompted to reason step by step, commonly referred to as chain-of-thought (CoT) reasoning. While prior work has proposed mechanism-level approaches to evaluate CoT faithfulness, these studies have primarily focused on English, leaving low-resource languages such as Persian largely underexplored. In this paper, we present the first comprehensive study of CoT faithfulness in Persian. Our analysis spans 15 classification datasets and 6 language models across three classes (small, large, and reasoning models) evaluated under both English and Persian prompting conditions. We first assess model performance on each dataset while collecting the corresponding CoT traces and final predictions. We then evaluate the faithfulness of these CoT traces using an LLM-as-a-judge approach, followed by a human evaluation to measure agreement between the LLM-based judge and human annotator. Our results reveal substantial variation in CoT faithfulness across tasks, datasets, and model classes. In particular, faithfulness is strongly influenced by the dataset and the language model class, while the language used for prompting has a comparatively smaller effect. Notably, small language models exhibit lower or comparable faithfulness scores than large language models and reasoning models.
@inproceedings{yazdani-etal-2026-comprehensive,
title = "A Comprehensive Evaluation of Chain-of-Thought Faithfulness in {P}ersian Classification Tasks",
author = "Yazdani, Shakib and
Espa{\~n}a-Bonet, Cristina and
Avramidis, Eleftherios and
Hamidullah, Yasser and
van Genabith, Josef",
editor = "Hettiarachchi, Hansi and
Ranasinghe, Tharindu and
Plum, Alistair and
Rayson, Paul and
Mitkov, Ruslan and
Gaber, Mohamed and
Premasiri, Damith and
Tan, Fiona Anting and
Uyangodage, Lasitha",
booktitle = "Proceedings of the Second Workshop on Language Models for Low-Resource Languages ({L}o{R}es{LM} 2026)",
month = mar,
year = "2026",
address = "Rabat, Morocco",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2026.loreslm-1.27/",
doi = "10.18653/v1/2026.loreslm-1.27",
pages = "311--323",
ISBN = "979-8-89176-377-7"
}
LaFresCat: A studio-quality Catalan multi-accent speech dataset for text-to-speech synthesis
Alex Peiró-Lilja, Carme Armentano-Oller, José Giraldo, Wendy Elvira-García, Ignasi Esquerra, Rodolfo Zevallos, Cristina España-Bonet, Martí Llopart-Font, Baybars Külebi and Mireia Farrús
Computer Speech & Language, 100:101945, 2026.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Current text-to-speech (TTS) systems are capable of learning the phonetics of a language accurately given that the speech data used to train such models covers all phonetic phenomena. For languages with different varieties, this includes all their richness and accents. This is the case of Catalan, a mid-resourced language with several dialects or accents. Although there are various publicly available corpora, there is a lack of high-quality open-access data for speech technologies covering its variety of accents. Common Voice includes recordings of Catalan speakers from different regions; however, accent labeling has been shown to be inaccurate, and artificially enhanced samples may be unsuitable for TTS. To address these limitations, we present LaFresCat, the first studio-quality Catalan multi-accent dataset. LaFresCat comprises 3.5 h of professionally recorded speech covering four of the most prominent Catalan accents: Balearic, Central, North-Western, and Valencian. In this work, we provide a detailed description of the dataset design: utterances were selected to be phonetically balanced, detailed speaker instructions were provided, native speakers from the regions corresponding to the Catalan accents were hired, and the recordings were formatted and post-processed. The resulting dataset, LaFresCat, is publicly available. To preliminarily evaluate the dataset, we trained and assessed a lightweight flow-based TTS system, which is also provided as a by-product. We also analyzed LaFresCat samples and the corresponding TTS-generated samples at the phonetic level, employing expert annotations and Pillai scores to quantify acoustic vowel overlap. Preliminary results suggest a significant improvement in predicted mean opinion score (UTMOS), with an increase of 0.42 points when the TTS system is fine-tuned on LaFresCat rather than trained from scratch, starting from a pre-trained version based on Central Catalan data from Common Voice. Subsequent human expert annotations achieved nearly 90% accuracy in accent classification for LaFresCat recordings. However, although the TTS tends to homogenize pronunciation, it still learns distinct dialectal patterns. This assessment offers key insights for establishing a baseline to guide future evaluations of Catalan multi-accent TTS systems and further studies of LaFresCat.
@article{peiroEtAl:CSL25,
title = {LaFresCat: A studio-quality Catalan multi-accent speech dataset for text-to-speech synthesis},
journal = {Computer Speech & Language},
volume = {100},
pages = {101945},
year = {2026},
issn = {0885-2308},
doi = {https://doi.org/10.1016/j.csl.2026.101945},
url = {https://www.sciencedirect.com/science/article/pii/S0885230826000082},
author = {Alex Peir\'o-Lilja and Carme Armentano-Oller and Jos\'e Giraldo and Wendy Elvira-Garc\'ia and
Ignasi Esquerra and Rodolfo Zevallos and Cristina Espa{\~n}a-Bonet and Mart\'i Llopart-Font and
Baybars K\"ulebi and Mireia Farr\'us},
keywords = {Human-produced speech data, Text-to-speech, Catalan}
}
2025
AFRIDOC-MT: Document-level MT Corpus for African Languages
Jesujoba O. Alabi, Israel Abebe Azime, Miaoran Zhang, Cristina España-Bonet, Rachel Bawden, Dawei Zhu, David Ifeoluwa Adelani, Clement Oyeleke Odoje, Idris Akinade, Iffat Maab, Davis David, Shamsuddeen Hassan Muhammad, Neo Putini, David O. Ademuyiwa, Andrew Caines and Dietrich Klakow
In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 25), pages 27758-27794, Suzhou, China. Association for Computational Linguistics. November 2025.
[
Abstract
PDF
Poster
Slides
BibTeX
]
This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yoruba and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating neural machine translation (NMT) models and large language models (LLMs) for translations between English and these languages, at both the sentence and pseudo-document levels. These outputs are realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieved the best average performance among the standard NMT models, while GPT-4o outperformed general-purpose LLMs. Fine-tuning selected models led to substantial performance gains, but models trained on sentences struggled to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, repetition of words or phrases, and off-target translations, especially for African languages.
@inProceedings{alabi2025afridoc,
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.emnlp-main.1413/",
pages = "27758--27794",
ISBN = "979-8-89176-332-6",
abstract = "This paper introduces AFRIDOC-MT, a document-level multi-parallel translation dataset covering English and five African languages: Amharic, Hausa, Swahili, Yor{\`u}b{\'a}, and Zulu. The dataset comprises 334 health and 271 information technology news documents, all human-translated from English to these languages. We conduct document-level translation benchmark experiments by evaluating the ability of neural machine translation (NMT) models and large language models (LLMs) to translate between English and these languages, at both the sentence and pseudo-document levels, the outputs being realigned to form complete documents for evaluation. Our results indicate that NLLB-200 achieves the best average performance among the standard NMT models, while GPT-4o outperforms general-purpose LLMs. Fine-tuning selected models leads to substantial performance gains, but models trained on sentences struggle to generalize effectively to longer documents. Furthermore, our analysis reveals that some LLMs exhibit issues such as under-generation, over-generation, repetition of words and phrases, and off-target translations, specifically for translation into African languages."
}
SONAR-SLT: Multilingual Sign Language Translation via Language-Agnostic Sentence Embedding Supervision
Yasser Hamidullah, Shakib Yazdani, Cennet Oguz, Josef van Genabith and Cristina España-Bonet
In Proceedings of the Tenth Conference on Machine Translation (WMT 2025), pages 301-313, Suzhou, China. Association for Computational Linguistics. November 2025.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Sign language translation (SLT) is typically trained with text in a single spoken language, which limits scalability and cross-language generalization. Earlier approaches have replaced gloss supervision with text-based sentence embeddings, but up to now, these remain tied to a specific language and modality. In contrast, here we employ language-agnostic, multimodal embeddings trained on text and speech from multiple languages to supervise SLT, enabling direct multilingual translation. To address data scarcity, we propose a coupled augmentation method that combines multilingual target augmentations (i.e. translations into many languages) with video-level perturbations, improving model robustness. Experiments show consistent BLEURT gains over text-only sentence embedding supervision, with larger improvements in low-resource settings. Our results demonstrate that language-agnostic embedding supervision, combined with coupled augmentation, provides a scalable and semantically robust alternative to traditional SLT training.
@inproceedings{hamidullah-etal-2025-sonar,
title = "{SONAR}-{SLT}: Multilingual Sign Language Translation via Language-Agnostic Sentence Embedding Supervision",
author = "Hamidullah, Yasser and Yazdani, Shakib and Oguz, Cennet and van Genabith, Josef and Espa{\~n}a-Bonet, Cristina",
editor = "Haddow, Barry and Kocmi, Tom and Koehn, Philipp and Monz, Christof",
booktitle = "Proceedings of the Tenth Conference on Machine Translation",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.wmt-1.18/",
pages = "301--313",
ISBN = "979-8-89176-341-8",
abstract = "Sign language translation (SLT) is typically trained with text in a single spoken language, which limits scalability and cross-language generalization. Earlier approaches have replaced gloss supervision with text-based sentence embeddings, but up to now, these remain tied to a specific language and modality. In contrast, here we employ language-agnostic, multimodal embeddings trained on text and speech from multiple languages to supervise SLT, enabling direct multilingual translation. To address data scarcity, we propose a coupled augmentation method that combines multilingual target augmentations (i.e. translations into many languages) with video-level perturbations, improving model robustness. Experiments show consistent BLEURT gains over text-only sentence embedding supervision, with larger improvements in low-resource settings. Our results demonstrate that language-agnostic embedding supervision, combined with coupled augmentation, provides a scalable and semantically robust alternative to traditional SLT training."
}
Seeing, Signing, and Saying: A Vision-Language Model-Assisted Pipeline for Sign Language Data Acquisition and Curation from Social Media
Shakib Yazdani, Yasser Hamidullah, Cristina España-Bonet and Josef van Genabith
In Proceedings of the 15th International Conference on Recent Advances in Natural Language Processing (RANLP 2025), INCOMA Ltd., pages 1374-1384. Shoumen, Bulgaria, September 2025.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Most existing sign language translation (SLT) datasets are limited in scale, lack multilingual coverage, and are costly to curate due to their reliance on expert annotation and controlled recording setup. Recently, Vision Language Models (VLMs) have demonstrated strong capabilities as evaluators and real-time assistants. Despite these advancements, their potential remains untapped in the context of sign language dataset acquisition. To bridge this gap, we introduce the first automated annotation and filtering framework that utilizes VLMs to reduce reliance on manual effort while preserving data quality. Our method is applied to TikTok videos across eight sign languages and to the already curated YouTube-SL-25 dataset in German Sign Language for the purpose of additional evaluation. Our VLM-based pipeline includes a face visibility detection, a sign activity recognition, a text extraction from video content, and a judgment step to validate alignment between video and text, implementing generic filtering, annotation and validation steps. Using the resulting corpus, TikTok-SL-8, we assess the performance of two off-the-shelf SLT models on our filtered dataset for German and American Sign Languages, with the goal of establishing baselines and evaluating the robustness of recent models on automatically extracted, slightly noisy data. Our work enables scalable, weakly supervised pretraining for SLT and facilitates data acquisition from social media.
@InProceedings{yazdaniEtAl:RANLP25,
author = {Yazdani, Shakib and Hamidullah, Yasser and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef},
title = {Seeing, Signing, and Saying: A Vision-Language Model-Assisted Pipeline for Sign Language Data Acquisition and Curation from Social Media},
booktitle = {Proceedings of the 15th International Conference on Recent Advances in Natural Language Processing - Natural Language Processing in the Generative AI era},
month = {September},
year = {2025},
address = {Varna, Bulgaria},
publisher = {INCOMA Ltd., Shoumen, Bulgaria},
pages = {1374--1384},
abstract = {Most existing sign language translation (SLT) datasets are limited in scale, lack multilingual coverage, and are costly to curate due to their reliance on expert annotation and controlled recording setup. Recently, Vision Language Models (VLMs) have demonstrated strong capabilities as evaluators and real-time assistants. Despite these advancements, their potential remains untapped in the context of sign language dataset acquisition. To bridge this gap, we introduce the first automated annotation and filtering framework that utilizes VLMs to reduce reliance on manual effort while preserving data quality. Our method is applied to TikTok videos across eight sign languages and to the already curated YouTube-SL-25 dataset in German Sign Language for the purpose of additional evaluation. Our VLM-based pipeline includes a face visibility detection, a sign activity recognition, a text extraction from video content, and a judgment step to validate alignment between video and text, implementing generic filtering, annotation and validation steps. Using the resulting corpus, TikTok-SL-8, we assess the performance of two off-the-shelf SLT models on our filtered dataset for German and American Sign Languages, with the goal of establishing baselines and evaluating the robustness of recent models on automatically extracted, slightly noisy data. Our work enables scalable, weakly supervised pretraining for SLT and facilitates data acquisition from social media.},
url = {https://aclanthology.org/2025.ranlp-1.159}
}
Evaluating Speech Enhancement Performance Across Demographics and Language
Jose Giraldo, Alex Peiró-Lilja, Carme Armentano-Oller, Rodolfo Zevallos and Cristina España-Bonet
In Proceedings of Interspeech 2025, pages 1353-1357, Rotterdam, Netherlands, August 2025.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Speech enhancement models have traditionally relied on VoiceBank-DEMAND for training and evaluation. However, this dataset presents significant limitations due to its limited diversity and simulated noise conditions. As an alternative, we propose and demonstrate the usefulness of evaluating the generalization capabilities of recent speech enhancement models using CommonPhone, a multilingual and crowdsourced dataset. Since CommonPhone is derived from CommonVoice, it allows to analyze enhancement performance based on demographic variables such as age and gender. Our experiments reveal significant performance variations across these variables. We also introduce a new benchmark dataset designed to challenge enhancement models with difficult and diverse speech samples, facilitating future research in universal speech enhancement.
@inproceedings{giraldo25_interspeech,
title = {{Evaluating Speech Enhancement Performance Across Demographics and Language}},
author = {{Jose Giraldo and Alex Peir\'o-Lilja and Carme Armentano-Oller and Rodolfo Zevallos and Cristina Espa{\~n}a-Bonet}},
year = {{2025}},
month = aug,
address = {{Rotterdam, Netherlands}},
booktitle = {{Interspeech 2025}},
pages = {{1353--1357}},
doi = {{10.21437/Interspeech.2025-1760}},
issn = {{2958-1796}}
}
Towards Domain-Specific Spoken Language Understanding for a Catalan Voice-Controlled Video Game
Alex Peiró-Lilja, Rodolfo Zevallos, Carme Armentano-Oller, Jose Giraldo, Cristina España-Bonet and Mireia Farrús
In Proceedings of Interspeech 2025, pages 4965-4966, Rotterdam, Netherlands, August 2025.
[
Abstract
PDF
Poster
Slides
BibTeX
]
We design a voice-controlled video game to integrate Catalan into gaming using speech technologies developed under the Aina project. The game is designed to elicit natural speech commands from players. However, a significant challenge in this endeavor is the limited availability of Catalan-language Spoken Language Understanding (SLU) datasets, especially those covering specialized linguistic domains relevant to interactive gaming environments. To address this, we implement a cascading SLU system that combines automatic speech recognition (ASR) with roBERTa-based models previously trained in Catalan. The latter was finetuned as a multi-task classifier by generating synthetic transcriptions from a small set of human-written examples. With acceptable accuracy and time inference, our goal is to evaluate its performance in-game and gather feedback from users.
@inproceedings{peirolilja25_interspeech,
title = {{Towards Domain-Specific Spoken Language Understanding for a Catalan Voice-Controlled Video Game}},
author = {{Alex Peir\'o-Lilja and Rodolfo Zevallos and Carme Armentano-Oller and Jose Giraldo and Cristina Espa{\~n}a-Bonet and Mireia Farr\'us}},
year = {{2025}},
month = aug,
address = {{Rotterdam, Netherlands}},
booktitle = {{Interspeech 2025}},
pages = {{4965--4966}},
issn = {{2958-1796}}
}
MultiCoPIE: A Multilingual Corpus of Potentially Idiomatic Expressions for Cross-lingual PIE Disambiguation (BEST PAPER AWARD)
Uliana Sentsova, Debora Ciminari, Josef van Genabith and Cristina España-Bonet
In Proceedings of the 21st Workshop on Multiword Expressions (MWE 2025), pages 67-81, Albuquerque, New Mexico, U.S.A.. Association for Computational Linguistics, May 2025.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Language models are able to handle compositionality and, to some extent, non-compositional phenomena such as semantic idiosyncrasy, a feature most prominent in the case of idioms. This work introduces the MultiCoPIE corpus that includes potentially idiomatic expressions in Catalan, Italian, and Russian, extending the language coverage of PIE corpus data. The new corpus provides additional linguistic features of idioms, such as their semantic compositionality, part-of-speech of idiom head as well as their corresponding idiomatic expressions in English. With this new resource at hand, we first fine-tune an XLM-RoBERTa model to classify figurative and literal usage of potentially idiomatic expressions in English. We then study cross-lingual transfer to the languages represented in the MultiCoPIE corpus, evaluating the model's ability to generalize an idiom-related task to languages not seen during fine-tuning. We show the effect of 'cross-lingual lexical overlap': the performance of the model, fine-tuned on English idiomatic expressions and tested on the MultiCoPIE languages, increases significantly when classifying 'shared idioms' -idiomatic expressions that have direct counterparts in English with similar form and meaning. While this observation raises questions about the generalizability of cross-lingual learning, the results from experiments on PIEs demonstrate strong evidence of effective cross-lingual transfer, even when accounting for idioms similar across languages.
@inproceedings{sentsova-etal-2025-multicopie,
title = "{M}ulti{C}o{PIE}: A Multilingual Corpus of Potentially Idiomatic Expressions for Cross-lingual {PIE} Disambiguation",
author = "Sentsova, Uliana and
Ciminari, Debora and
Genabith, Josef Van and
Espa{\~n}a-Bonet, Cristina",
editor = {Ojha, Atul Kr. and
Giouli, Voula and
Mititelu, Verginica Barbu and
Constant, Mathieu and
Korvel, Gra{\v{z}}ina and
Do{\u{g}}ru{\"o}z, A. Seza and
Rademaker, Alexandre},
booktitle = "Proceedings of the 21st Workshop on Multiword Expressions (MWE 2025)",
month = may,
year = "2025",
address = "Albuquerque, New Mexico, U.S.A.",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.mwe-1.8/",
pages = "67--81",
ISBN = "979-8-89176-243-5"
}
Continual Learning in Multilingual Sign Language Translation
Shakib Yazdani, Josef van Genabith and Cristina España-Bonet
In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2025), Association for Computational Linguistics, pages 10923-10938. Albuquerque, New Mexico, May 2025.
[
Abstract
PDF
Poster
Slides
BibTeX
]
The field of sign language translation (SLT) is still in its infancy, as evidenced by the low translation quality, even when using deep learning approaches. Probably because of this, many common approaches in other machine learning fields have not been explored in sign language. Here, we focus on continual learning for multilingual SLT. We experiment with three continual learning methods and compare them to four more naive baseline and fine-tuning approaches. We work with four sign languages (ASL, BSL, CSL and DGS) and three spoken languages (Chinese, English and German). Our results show that incremental fine-tuning is the best performing approach both in terms of translation quality and transfer capabilities, and that continual learning approaches are not yet fully competitive given the current SOTA in SLT.
@inproceedings{continual-learning-slt,
title = "Continual Learning in Multilingual Sign Language Translation",
author = "Yazdani, Shakib and van Genabith, Josef and Espa{\~n}a-Bonet, Cristina"
editor = "Chiruzzo, Luis and
Ritter, Alan and
Wang, Lu",
booktitle = "Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
month = apr,
year = "2025",
address = "Albuquerque, New Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.naacl-long.546/",
pages = "10923--10938",
ISBN = "979-8-89176-189-6"
}
2024
Analysing Translation Artifacts: A Comparative Study of LLMs, NMTs, and Human Translations
Fedor Sizov, Cristina España-Bonet, Josef van Genabith, Roy Xie and Koel Dutta Chowdhury
In Proceedings of the Proceedings of the Ninth Conference on Machine Translation (WMT 2024), pages 1183-1199. Miami, United States of America, November 2024.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Translated texts exhibit a range of characteristics that make them appear distinct from texts originally written in the same target language. With the rise of Large Language Models (LLMs), which are designed for a wide range of language generation and understanding tasks, there has been significant interest in their application to Machine Translation. While several studies have focused on improving translation quality through fine-tuning or few-shot prompting techniques, there has been limited exploration of how LLM-generated translations qualitatively differ from those produced by Neural Machine Translation (NMT) models, and human translations. Our study employs explainability methods such as Leave-One-Out (LOO) and Integrated Gradients (IG) to analyze the lexical features distinguishing human translations from those produced by LLMs and NMT systems. Specifically, we apply a two-stage approach: first, classifying texts based on their origin —whether they are original or translations— and second, extracting significant lexical features (highly attributed input words) using post-hoc interpretability methods. Our analysis shows that different methods of feature extraction vary in their effectiveness, with LOO being generally better at pinpointing critical input words and IG capturing a broader range of important words. Finally, our results show that while LLMs and NMT systems can produce translations of a good quality, they still differ from texts originally written by native speakers. We find that while some LLMs more closely resemble human translations, traditional NMT systems show distinct differences, particularly in their use of linguistic features.
@inproceedings{sizov-etal-2024-analysing,
title = "Analysing Translation Artifacts: A Comparative Study of {LLM}s, {NMT}s, and Human Translations",
author = "Sizov, Fedor and
Espa{\~n}a-Bonet, Cristina and
Van Genabith, Josef and
Xie, Roy and
Dutta Chowdhury, Koel",
editor = "Haddow, Barry and
Kocmi, Tom and
Koehn, Philipp and
Monz, Christof",
booktitle = "Proceedings of the Ninth Conference on Machine Translation",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.wmt-1.116",
doi = "10.18653/v1/2024.wmt-1.116",
pages = "1183--1199"
}
Introduction to Multilingual and Multicultural NLP
Cristina España-Bonet
Tutorial at the DisAI Summer School on trustworthy, multilingual and multimodal AI, September 3rd-6th, Bratislava, Slovakia, 2024.
Sign Language Translation with Sentence Embedding Supervision
Yasser Hamidullah, Josef van Genabith and Cristina España-Bonet
In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), Association for Computational Linguistics, pages 425-434. Bangkok, Thailand, August 2024.
[
Abstract
PDF
Poster
Slides
BibTeX
]
State-of-the-art sign language translation systems facilitate the learning task through gloss annotations, either in an end2end manner or by involving an intermediate step. Unfortunately, gloss labelled sign language data is usually not available at scale and, when available, gloss annotations widely differ from dataset to dataset. We present a novel approach using sentence embeddings of the target sentences at training time that take the role of glosses. The new kind of supervision does not need any manual human annotation but is learned on raw textual data. As our approach easily facilitates multilinguality, we evaluate it on datasets covering German (PHOENIX-2014T) and American (How2Sign) sign languages and experiment with mono- and multilingual sentence embeddings and translation systems. Our approach significantly outperforms other gloss-free approaches, setting the new state-of-the-art for data sets where glosses are not available, and diminishing the gap between gloss-free and gloss-dependent systems.
@inproceedings{alt-sentence-embeddings,
title = "Sign Language Translation with Sentence Embedding Supervision",
author = {Yasser Hamidullah, Josef van Genabith and Cristina Espa{\~n}a-Bonet},
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-short.40",
pages = "425--434"
}
Elote, Choclo and Mazorca: on the Varieties of Spanish
Cristina España-Bonet and Alberto Barrón-Cedeño
In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2024), Association for Computational Linguistics, pages 3689-3711. Mexico City, Mexico, June 2024.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Spanish is one of the most widespread languages: the official language in 20 countries and the second most-spoken native language. Its contact with other languages across different regions and the rich regional and cultural diversity has produced varieties which divert from each other, particularly in terms of lexicon. Still, available corpora, and models trained upon them, generally treat Spanish as one monolithic language, which dampers prediction and generation power when dealing with different varieties. To alleviate the situation, we compile and curate datasets in the different varieties of Spanish around the world at an unprecedented scale and create the CEREAL corpus. With such a resource at hand, we perform a stylistic analysis to identify and characterise varietal differences. We implement a classifier specially designed to deal with long documents and identify Spanish varieties (and therefore expand CEREAL further). We produce varietal-specific embeddings, and analyse the cultural differences that they encode. We make data, code and models publicly available.
@inproceedings{elote-varieties,
title = "Elote, Choclo and Mazorca: on the Varieties of Spanish ",
author = "Espa{\~n}a-Bonet, Cristina and Barr\'on-Cede{\~n}o, Alberto"
booktitle = "Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2024",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.naacl-long.204.pdf",
pages = "3689--3711"
}
When Elote, Choclo and Mazorca are not the Same. Isomorphism-Based Perspective to the Spanish Varieties Divergences
Cristina España-Bonet, Ankur Bhatt, Koel Dutta Chowdhury, Alberto Barrón-Cedeño
In Proceedings the Eleventh Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2024), Association for Computational Linguistics, pages 56-77. Mexico City, Mexico, June 2024.
[
Abstract
PDF
PDF
Slides
BibTeX
]
Spanish is an official language in 20 countries; in 19 of them, it arrived by means of overseas colonisation. Its close contact with several coexisting languages and the rich regional and cultural diversity has produced varieties that divert from each other. We study these divergences with a data-based approach and according to their qualitative and quantitative effects in word embeddings. We generate embeddings for Spanish in 24 countries and examine the topology of the spaces. Due to the similarities between varieties —in contrast to what happens to different languages in bilingual topological studies— we first scrutinise the behaviour of three isomorphism measures in (quasi-)isomorphic settings: relational similarity, Eigenvalue similarity, and Gromov-Hausdorff distance. We then use the most trustworthy measure to quantify the divergences among varieties. Finally, we use the departures from isomorphism to build relational trees for the Spanish varieties by hierarchical clustering, and observe that voseo is the phenomenon that leaves the strongest imprint in the embeddings.
@inproceedings{elote-isomorphism,
title = "When Elote, Choclo and Mazorca are not the Same. Isomorphism-Based Perspective to the Spanish Varieties Divergences",
author = "Espa{\~n}a-Bonet, Cristina and Bhatt, Ankur and Chowdhury, Koel Dutta and Barr\'on-Cede{\~n}o, Alberto",
booktitle = "Proceedings of the Eleventh Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2024)",
month = jun,
year = "2024",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.vardial-1.5.pdf",
pages = "56--77"
}
Mitigating Translationese with GPT-4: Strategies and Performance
Maria Kunilovskaya, Koel Dutta Chowdhury, Heike Przybyl, Cristina España-Bonet, Josef van Genabith
In Proceedings of the 25th Annual Conference of the European Association for Machine Translation (EAMT 2024), pages 411-430. Sheffield, United Kingdom, June 2024.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Translations into a language differ in systematic ways from text originally authored in the same language. These differences, collectively known as translationese, can pose challenges in cross-lingual natural language processing: models trained or tested on translated input might struggle when presented with non-translated language. This study investigates the generative capacities of GPT-4 to reduce translationese in human-translated texts. The task is framed as a rewriting process aimed at a translation variant indistinguishable from the original text in the target language. The focus of the paper is on prompt engineering that tests the utility of linguistic knowledge as part of the instruction for the LLM. Through a series of prompt design experiments, we show that the GPT4-generated revisions are more similar to originals in the target language when the prompts incorporate specific linguistic instructions instead of relying solely on the model's internal knowledge. We release the segment-aligned bidirectional German-English data built from the Europarl corpus that underpins this study.
@inproceedings{mitigating-translationese-gpt4,
title = "Mitigating Translationese with GPT-4: Strategies and Performance",
author = "Kunilovskaya, Maria and Chowdhury, Koel and Przybyl, Heike and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef",
booktitle = "Proceedings of the 25th Annual Conference of the European Association for Machine Translation",
month = jun,
year = "2024",
address = "Sheffield, United Kingdom",
publisher = "European Association for Machine Translation",
url = "https://eamt2024.github.io/proceedings/vol1.pdf",
pages = "411--430"
}
When Your Cousin Has the Right Connections: Unsupervised Bilingual Lexicon Induction for Related Data-Imbalanced Languages (BEST STUDENT PAPER AWARD)
Niyati Bafna, Cristina España-Bonet, Josef van Genabith, Benoît Sagot, Rachel Bawden
In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 17544â17556, Torino, Italia. ELRA and ICCL, May 2024.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Most existing approaches for unsupervised bilingual lexicon induction (BLI) depend on good quality static or contextual embeddings requiring large monolingual corpora for both languages. However, unsupervised BLI is most likely to be useful for low-resource languages (LRLs), where large datasets are not available. Often we are interested in building bilingual resources for LRLs against related high-resource languages (HRLs), resulting in severely imbalanced data settings for BLI. We first show that state-of-the-art BLI methods in the literature exhibit near-zero performance for severely data-imbalanced language pairs, indicating that these settings require more robust techniques. We then present a new method for unsupervised BLI between a related LRL and HRL that only requires inference on a masked language model of the HRL, and demonstrate its effectiveness on truly low-resource languages Bhojpuri and Magahi (with <5M monolingual tokens each), against Hindi. We further present experiments on (mid-resource) Marathi and Nepali to compare approach performances by resource range, and release our resulting lexicons for five low-resource Indic languages: Bhojpuri, Magahi, Awadhi, Braj, and Maithili, against Hindi.
@inproceedings{bafna-etal-2024-cousin-right,
title = "When Your Cousin Has the Right Connections: Unsupervised Bilingual Lexicon Induction for Related Data-Imbalanced Languages",
author = "Bafna, Niyati and
Espa{\~n}a-Bonet, Cristina and
van Genabith, Josef and
Sagot, Beno{\^\i}t and
Bawden, Rachel",
editor = "Calzolari, Nicoletta and
Kan, Min-Yen and
Hoste, Veronique and
Lenci, Alessandro and
Sakti, Sakriani and
Xue, Nianwen",
booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)",
month = may,
year = "2024",
address = "Torino, Italia",
publisher = "ELRA and ICCL",
url = "https://aclanthology.org/2024.lrec-main.1526",
pages = "17544--17556"
}
DGS-Fabeln-1: A Multi-Angle Parallel Corpus of Fairy Tales between German Sign Language and German Text
Fabrizio Nunnari, Eleftherios Avramidis, Cristina España-Bonet, Marco González, Anna Hennes, and Patrick Gebhard
In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 4847â4857, Torino, Italia. ELRA and ICCL, May 2024.
[
Abstract
PDF
Poster
Slides
BibTeX
]
We present the acquisition process and the data of DGS-Fabeln-1, a parallel corpus of German text and videos containing German fairy tales interpreted into the German Sign Language (DGS) by a native DGS signer. The corpus contains 573 segments of videos with a total duration of 1 hour and 32 minutes, corresponding with 1428 written sentences. It is the first corpus of semi-naturally expressed DGS that has been filmed from 7 angles, and one of the few sign language (SL) corpora globally which have been filmed from more than 3 angles and where the listener has been simultaneously filmed. The corpus aims at aiding research at SL linguistics, SL machine translation and affective computing, and is freely available for research purposes at the following address: https://doi.org/10.5281/zenodo.10822097.
@inproceedings{nunnari-etal-2024-dgs-fabeln,
title = "{DGS}-Fabeln-1: A Multi-Angle Parallel Corpus of Fairy Tales between {G}erman {S}ign {L}anguage and {G}erman Text",
author = "Nunnari, Fabrizio and
Avramidis, Eleftherios and
Espa{\~n}a-Bonet, Cristina and
Gonz{\'a}lez, Marco and
Hennes, Anna and
Gebhard, Patrick",
editor = "Calzolari, Nicoletta and
Kan, Min-Yen and
Hoste, Veronique and
Lenci, Alessandro and
Sakti, Sakriani and
Xue, Nianwen",
booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)",
month = may,
year = "2024",
address = "Torino, Italia",
publisher = "ELRA and ICCL",
url = "https://aclanthology.org/2024.lrec-main.434",
pages = "4847--4857"
}
2023
Multilingual Coarse Political Stance Classification of Media. The Editorial Line of a ChatGPT and Bard Newspaper
Cristina España-Bonet
In Findings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 11757â11777, Singapore (hybrid). Association for Computational Linguistics, December 2023.
[
Abstract
PDF
Poster
Slides
BibTeX
]
Neutrality is difficult to achieve and, in politics, subjective. Traditional media typically adopt an editorial line that can be used by their potential readers as an indicator of the media bias. Several platforms currently rate news outlets according to their political bias. The editorial line and the ratings help readers in gathering a balanced view of news. But in the advent of instruction-following language models, tasks such as writing a newspaper article can be delegated to computers. Without imposing a biased persona, where would an AI-based news outlet lie within the bias ratings? In this work, we use the ratings of authentic news outlets to create a multilingual corpus of news with coarse stance annotations (Left and Right) along with automatically extracted topic annotations. We show that classifiers trained on this data are able to identify the editorial line of most unseen newspapers in English, German, Spanish and Catalan. We then apply the classifiers to 101 newspaper-like articles written by ChatGPT and Bard in the 4 languages at different time periods. We observe that, similarly to traditional newspapers, ChatGPT editorial line evolves with time and, being a data-driven system, the stance of the generated articles differs among languages.
@inproceedings{espana-bonet:2023,
title = "Multilingual Coarse Political Stance Classification of Media. The Editorial Line of a {C}hat{GPT} and Bard Newspaper",
author = "Espa{\~n}a-Bonet, Cristina",
editor = "Bouamor, Houda and Pino, Juan and Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.787",
doi = "10.18653/v1/2023.findings-emnlp.787",
pages = "11757--11777"
}
Translating away Translationese without Parallel Data
Rricha Jalota, Koel Chowdhury, Cristina España-Bonet and Josef van Genabith
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7086â7100, Singapore (hybrid). Association for Computational Linguistics, December 2023.
[
Abstract
PDF
BibTeX
]
Translated texts exhibit systematic linguistic differences compared to original texts in the same language, and these differences are referred to as translationese. Translationese has effects on various cross-lingual natural language processing tasks, potentially leading to biased results. In this paper, we explore a novel approach to reduce translationese in translated texts: translation-based style transfer. As there are no parallel human-translated and original data in the same language, we use a self-supervised approach that can learn from comparable (rather than parallel) mono-lingual original and translated data. However, even this self-supervised approach requires some parallel data for validation. We show how we can eliminate the need for parallel validation data by combining the self-supervised loss with an unsupervised loss. This unsupervised loss leverages the original language model loss over the style-transferred output and a semantic similarity loss between the input and style-transferred output. We evaluate our approach in terms of original vs. translationese binary classification in addition to measuring content preservation and target-style fluency. The results show that our approach is able to reduce translationese classifier accuracy to a level of a random classifier after style transfer while adequately preserving the content and fluency in the target original style.
@inproceedings{jalotaEtAl:2023,
title = "Translating away Translationese without Parallel Data",
author = "Jalota, Rricha and Chowdhury, Koel and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef",
editor = "Bouamor, Houda and Pino, Juan and Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.438",
doi = "10.18653/v1/2023.emnlp-main.438",
pages = "7086--7100"
}
Findings of the Second WMT Shared Task on Sign Language Translation (WMT-SLT23)
Mathias Müller, Malihe Alikhani, Eleftherios Avramidis, Richard Bowden, Annelies Braffort, Necati Cihan Camgöz, Sarah Ebling, Cristina España-Bonet, Anne Göhring, Roman Grundkiewicz, Mert Inan, Zifan Jiang, Oscar Koller, Amit Moryossef, Annette Rios, Dimitar Shterionov, Sandra Sidler-Miserez, Katja Tissi and Davy Van Landuyt
In Proceedings of the Eighth Conference on Machine Translation (WMT), pages 68â94, Singapore (hybrid). Association for Computational Linguistics. December 2023.
[
Abstract
PDF
BibTeX
]
This paper presents the results of the Second WMT Shared Task on Sign Language Translation (WMT-SLT23; https://www.wmt-slt.com/). This shared task is concerned with automatic translation between signed and spoken languages. The task is unusual in the sense that it requires processing visual information (such as video frames or human pose estimation) beyond the well-known paradigm of text-to-text machine translation (MT). The task offers four tracks involving the following languages: Swiss German Sign Language (DSGS), French Sign Language of Switzerland (LSF-CH), Italian Sign Language of Switzerland (LIS-CH), German, French and Italian. Four teams (including one working on a baseline submission) participated in this second edition of the task, all submitting to the DSGS-to-German track. Besides a system ranking and system papers describing state-of-the-art techniques, this shared task makes the following scientific contributions: novel corpora and reproducible baseline systems. Finally, the task also resulted in publicly available sets of system outputs and more human evaluation scores for sign language translation.
@inproceedings{muller-etal-2023-findings,
title = "Findings of the Second {WMT} Shared Task on Sign Language Translation ({WMT}-{SLT}23)",
author = {M{\"u}ller, Mathias and
Alikhani, Malihe and
Avramidis, Eleftherios and
Bowden, Richard and
Braffort, Annelies and
Cihan Camg{\"o}z, Necati and
Ebling, Sarah and
Espa{\~n}a-Bonet, Cristina and
G{\"o}hring, Anne and
Grundkiewicz, Roman and
Inan, Mert and
Jiang, Zifan and
Koller, Oscar and
Moryossef, Amit and
Rios, Annette and
Shterionov, Dimitar and
Sidler-Miserez, Sandra and
Tissi, Katja and
Van Landuyt, Davy},
editor = "Koehn, Philipp and
Haddow, Barry and
Kocmi, Tom and
Monz, Christof",
booktitle = "Proceedings of the Eighth Conference on Machine Translation",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.wmt-1.4",
doi = "10.18653/v1/2023.wmt-1.4",
pages = "68--94"
}
Measuring Spurious Correlation in Classification: ``Clever Hans'' in Translationese
Angana Borah, Daria Pylypenko, Cristina España-Bonet and Josef van Genabith
In Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing (RANLP), pages 196-206, Varna, Bulgaria (hybrid), September 2023.
[
Abstract
PDF
BibTeX
]
Recent work has shown evidence of ``Clever Hans'' behavior in high-performance neural translationese classifiers, where BERT-based classifiers capitalize on spurious correlations, in particular topic information, between data and target classification labels, rather than genuine translationese signals. Translationese signals are subtle (especially for professional translation) and compete with many other signals in the data such as genre, style, author, and, in particular, topic. This raises the general question of how much of the performance of a classifier is really due to spurious correlations in the data versus the signals actually targeted for by the classifier, especially for subtle target signals and in challenging (low resource) data settings. We focus on topic-based spurious correlation and approach the question from two directions: (i) where we have no knowledge about spurious topic information and its distribution in the data, (ii) where we have some indication about the nature of spurious topic correlations. For (i) we develop a measure from first principles capturing alignment of unsupervised topics with target classification labels as an indication of spurious topic information in the data. We show that our measure is the same as purity in clustering and propose a ``topic floor'' (as in a ``noise floor'') for classification. For (ii) we investigate masking of known spurious topic carriers in classification. Both (i) and (ii) contribute to quantifying and (ii) to mitigating spurious correlations.
@inproceedings{borahEtAl2023,
title = "Measuring Spurious Correlation in Classification: {``}Clever Hans{''} in Translationese",
author = "Borah, Angana and
Pylypenko, Daria and
Espa{\~n}a-Bonet, Cristina and
van Genabith, Josef",
editor = "Mitkov, Ruslan and
Angelova, Galia",
booktitle = "Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing",
month = sep,
year = "2023",
address = "Varna, Bulgaria",
publisher = "INCOMA Ltd., Shoumen, Bulgaria",
url = "https://aclanthology.org/2023.ranlp-1.22",
pages = "196--206"
}
Human Biases in Multilingual Models
Cristina España-Bonet
Invited talk at the Language In The Human Machine Era Workshop: Bridging the gap between technology and professionals, LITHME WG1-WG7, August 28th-30th, Budapest, Hungary, 2023.
[
Slides
Abstract
]
Some human preferences are universal. The odor of vanilla is perceived as pleasant all around the world. We expect neural models trained on human texts to exhibit these kind of preferences, i.e. biases, but we show that this is not always the case. We explore multilingual embedding models in 9 languages and, when possible, compare them under similar training conditions. We introduce and release CA-WEAT, multilingual cultural aware tests to quantify biases, and compare them to previous English-centric tests. Monolingual static embeddings do exhibit these universal human biases, but values differ across languages, being indeed far from universal. Biases are less evident in contextual models, to the point that the original human association might be reversed. Multilinguality proves to be another variable that attenuates and even reverses the effect of the bias, specially in contextual multilingual models. In order to explain this variance among models and languages, we examine the effect of asymmetries in the training corpus, departures from isomorphism in multilingual embedding spaces and discrepancies in the testing measures between languages.
Enriching WayúunaikiâSpanish Neural Machine Translation with Linguistic Information
Nora Graichen, Josef van Genabith and Cristina España-Bonet
In proceedings of the third Workshop on Natural Language Processing for Indigenous Languages of the Americas, pages 67-83, July 14th, Toronto, Canada (hybrid), 2023.
[
Abstract
PDF
BibTeX
]
We present the first neural machine translation system for the low-resource language pair WayunaikiSpanish and explore strategies to inject linguistic knowledge into the model to improve translation quality. We explore a wide range of methods and combine complementary approaches. Results indicate that incorporating linguistic information through linguistically motivated subword segmentation, factored models, and pretrained embeddings helps the system to generate improved translations, with the segmentation contributing the most.In order to evaluate translation quality in a general domain and go beyond the available religious domain data, we gather and make publicly available a new test set and supplementary material.Although translation quality as measured with automatic metrics is low, we hope these resources will facilitate and support further research on Wayunaiki.
@inproceedings{graichenEtAl2023,
title = "Enriching {W}ay{\'u}naiki--{S}panish Neural Machine Translation with Linguistic Information",
author = "Graichen, Nora and van Genabith, Josef and Espa{\~n}a-Bonet, Cristina",
booktitle = "Proceedings of the Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.americasnlp-1.9",
doi = "10.18653/v1/2023.americasnlp-1.9",
pages = "67--83",
abstract = "We present the first neural machine translation system for the low-resource language pair WayunaikiSpanish and explore strategies to inject linguistic knowledge into the model to improve translation quality. We explore a wide range of methods and combine complementary approaches. Results indicate that incorporating linguistic information through linguistically motivated subword segmentation, factored models, and pretrained embeddings helps the system to generate improved translations, with the segmentation contributing the most.In order to evaluate translation quality in a general domain and go beyond the available religious domain data, we gather and make publicly available a new test set and supplementary material.Although translation quality as measured with automatic metrics is low, we hope these resources will facilitate and support further research on Wayunaiki.",
}
Towards Incorporating 3D Space-Awareness Into an Augmented Reality Sign Language Interpreter
Fabrizio Nunnari, Eleftherios Avramidis, Vemburaj Yadav, Alain Pagani, Yasser Hamidullah, Sepideh Mollanorozy, Cristina España-Bonet, Emil Woop and Patrick Gebhard
In proceedings of the Eighth International Workshop on Sign Language Translation and Avatar Technology. International Workshop on Sign Language Translation and Avatar Technology (SLTAT-2023), located at ICASSP 2023, pages 1-5, June 10th, Rhodes, Greece, 2023.
[
Abstract
PDF
BibTeX
]
This paper describes the concept and the software architecture of a fully integrated system supporting a dialog between a deaf person and a hearing person through a virtual sign language interpreter (aka avatar) projected in the real space by an Augmented Reality device. In addition, a Visual Simultaneous Localization and Mapping system provides information about the 3D location of the objects recognized in the surrounding environment, allowing the avatar to orient, look and point towards the real location of discourse entities during the translation. The goal being to provide a modular architecture to test single software components in a fully integrated framework and move virtual sign language interpreters beyond the standard ``front-facing'' interaction paradigm.
@InProceedings{NunnariEtal:SLAT:2023,
author = {Fabrizio Nunnari, Eleftherios Avramidis, Vemburaj Yadav, Alain Pagani, Yasser Hamidullah, Sepideh Mollanorozy, Cristina Espa{\~n}a-Bonet, Emil Woop and Patrick Gebhard},
title = "Towards Incorporating 3D Space-Awareness Into an Augmented Reality Sign Language Interpreter",
booktitle = "Proceedings of the Eighth International Workshop on Sign Language Translation and Avatar Technology. International Workshop on Sign Language Translation and Avatar Technology (SLTAT-2023), located at ICASSP 2023",
month = june,
year = "2023",
address = "Rhodes, Greece",
publisher = "IEEE",
pages = "1--5"
}
Are the Best Multilingual Document Embeddings simply Based on Sentence Embeddings?
Sonal Sannigrahi, Josef van Genabith and Cristina España-Bonet
In proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (Findings), pages 2306-2316, May 2nd-4th, Dubrovnik, Croatia (hybrid), 2023.
[
Abstract
PDF
BibTeX
arXiv
]
Dense vector representations for textual data are crucial in modern NLP. Word embeddings and sentence embeddings estimated from raw texts are key in achieving state-of-the-art results in various tasks requiring semantic understanding. However, obtaining embeddings at the document level is challenging due to computational requirements and lack of appropriate data. Instead, most approaches fall back on computing document embeddings based on sentence representations. Although there exist architectures and models to encode documents fully, they are in general limited to English and few other high-resourced languages. In this work, we provide a systematic comparison of methods to produce document-level representations from sentences based on LASER, LaBSE, and Sentence BERT pre-trained multilingual models. We compare input token number truncation, sentence averaging as well as some simple windowing and in some cases new augmented and learnable approaches, on 3 multi- and cross-lingual tasks in 8 languages belonging to 3 different language families. Our task-based extrinsic evaluations show that, independently of the language, a clever combination of sentence embeddings is usually better than encoding the full document as a single unit, even when this is possible. We demonstrate that while a simple sentence average results in a strong baseline for classification tasks, more complex combinations are necessary for semantic tasks.
@InProceedings{SannigrahiEtal:EACL:2023,
author = {Sannigrahi, Sonal and van Genabith, Josef and Espa{\~n}a-Bonet, Cristina},
title = "Are the Best Multilingual Document Embeddings simply Based on Sentence Embeddings?",
booktitle = "Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Findings)",
month = may,
year = "2023",
address = "Dubrovnik, Croatia (hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/",
pages = "2306--2316"
}
Cross-lingual Strategies for Low-resource Language Modeling: A Study on Five Indic Dialects
Niyati Bafna, Cristina España-Bonet, Josef van Genabith, Benoît Sagoit and Rachel Bawden
In proceedings of the 30e Conférence sur le Traitement Automatique des Langues Naturelles (TALN), pages 28-42, June 5-9, Paris, France, 2023.
[
Abstract
PDF
BibTeX
]
Neural language models play an increasingly central role for language processing, given their success for a range of NLP tasks. In this study, we compare some canonical strategies in language modeling for low-resource scenarios, evaluating all models by their (finetuned) performance on a POS-tagging downstream task. We work with five (extremely) low-resource dialects from the Indic dialect continuum (Braj, Awadhi, Bhojpuri, Magahi, Maithili), which are closely related to each other and the standard mid-resource dialect, Hindi. The strategies we evaluate broadly include from-scratch pretraining, and cross-lingual transfer between the dialects as well as from different kinds of off-the-shelf multilingual models; we find that a model pretrained on other mid-resource Indic dialects and languages, with extended pretraining on target dialect data, consistently outperforms other models. We interpret our results in terms of dataset sizes, phylogenetic relationships, and corpus statistics, as well as particularities of this linguistic system.
@InProceedings{BafnaEtal:TALN:2023,
title="{Cross-lingual Strategies for Low-resource Language Modeling: A Study on Five Indic Dialects}",
author={Bafna, Niyati and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef and Sagot, Beno{\^\i}t and Bawden, Rachel},
booktitle={30e Conférence sur le Traitement Automatique des Langues Naturelles (TALN)},
pages={28--42},
year={2023},
address = {Paris, France},
organization={ATALA}
}
Tailoring and Evaluating the Wikipedia for in-Domain Comparable Corpora Extraction
Cristina España-Bonet, Alberto Barrón-Cedeño, Lluís Màrquez
Knowledge and Information Systems, Volum 65, pages 1365-1397. 2023. Springer-Verlag, London Ldt. https://doi.org/10.1007/s10115-022-01767-5
[
Abstract
PDF
BibTeX
arXiv (pre-review)
]
We propose a language-independent graph-based method to build à-la-carte article collections on user-defined domains from the Wikipedia. The core model is based on the exploration of the encyclopedia's category graph and can produce both mono- and multilingual comparable collections. We run thorough experiments to assess the quality of the obtained corpora in 10 languages and 743 domains. According to an extensive manual evaluation, our graph model reaches an average precision of 84\% on in-domain articles, outperforming an alternative model based on information retrieval techniques. As manual evaluations are costly, we introduce the concept of domainness and design several automatic metrics to account for the quality of the collections. Our best metric for domainness shows a strong correlation with human judgments, representing a reasonable automatic alternative to assess the quality of domain-specific corpora. We release the WikiTailor toolkit with the implementation of the extraction methods, the evaluation measures and several utilities.
@article{EspanaBonetEtal:2022,
author = {{Espa{\~n}a-Bonet}, Cristina and {Barr\'on-Cede{\~n}o}, Alberto and {M\`arquez}, Llu\'{i}s},
title = "{Tailoring and Evaluating the Wikipedia for in-Domain Comparable Corpora Extraction}",
journal = {Knowledge and Information Systems},
publisher = {Springer-Verlag},
address = {London, England},
keywords = {Comparable corpora, Wikipedia category graph, Domain-specific corpora, Domainness metrics},
doi = {10.1007/s10115-022-01767-5},
year = 2023,
vol = 65,
pages = {1365--1397}
}
2022
The (Undesired) Attenuation of Human Biases by Multilinguality
Cristina España-Bonet and Alberto Barrón-Cedeño
In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022), pages 2056-2077, Abu Dhabi, UAE (hybrid), 9-11 December, 2022.
[
Abstract
PDF
BibTeX
]
Some human preferences are universal. The odor of vanilla is perceived as pleasant all around the world. We expect neural models trained on human texts to exhibit these kind of preferences, i.e. biases, but we show that this is not always the case. We explore 16 static and contextual embedding models in 9 languages and, when possible, compare them under similar training conditions. We introduce and release CA-WEAT, multilingual cultural aware tests to quantify biases, and compare them to previous English-centric tests. Our experiments confirm that monolingual static embeddings do exhibit human biases, but values differ across languages, being far from universal. Biases are less evident in contextual models, to the point that the original human association might be reversed. Multilinguality proves to be another variable that attenuates and even reverses the effect of the bias, specially in contextual multilingual models. In order to explain this variance among models and languages, we examine the effect of asymmetries in the training corpus, departures from isomorphism in multilingual embedding spaces and discrepancies in the testing measures between languages.
@inproceedings{espana-bonet-etal-2022-attenuation,
title = "The (Undesired) Attenuation of Human Biases by Multilinguality",
author = "Espa{\~n}a-Bonet, Cristina and Barr\'on-Cede{\~n}o, Alberto",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE (hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.133",
pages = "2056--2077"
}
Explaining Translationese: why are Neural Classifiers Better and what do they Learn?
Kwabena Amponsah-Kaakyire, Daria Pylypenko, Josef van Genabith and Cristina España-Bonet
In proceedings of the fifth BlackBoxNLP Workshop, pages 281-296, December 8th, Abu Dhabi, UAE (hybrid), 2022.
[
Abstract
PDF
BibTeX
arXiv
]
Recent work has shown that neural feature- and representation-learning, e.g. BERT, achieves superior performance over traditional manual feature engineering based approaches, with e.g. SVMs, in translationese classification tasks. Previous research did not show (i) whether the difference is because of the features, the classifiers or both, and (ii) what the neural classifiers actually learn. To address (i), we carefully design experiments that swap features between BERT- and SVM-based classifiers. We show that an SVM fed with BERT representations performs at the level of the best BERT classifiers, while BERT learning and using handcrafted features performs at the level of an SVM using handcrafted features. This shows that the performance differences are due to the features. To address (ii) we use integrated gradients and find that $(a)$ there is indication that information captured by hand-crafted features is only a subset of what BERT learns, and (b) part of BERT's top performance results are due to BERT learning topic differences and spurious correlations with translationese.
@InProceedings{AmponsahEtal:Blackbox:2022,
author = {Amponsah-Kaakyire, Kwabena and Pylypenko, Daria and van Genabith, Josef and Espa{\~n}a-Bonet, Cristina},
title = "Explaining Translationese: why are Neural Classifiers Better and what do they Learn?",
booktitle = "Proceedings of the fifth BlackBoxNLP Workshop",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE (hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.blackboxnlp-1.23.pdf",
pages = "281--296"
}
Combining Noisy Semantic Signals with Orthographic Cues: Cognate Induction for the Indic Dialect Continuum
Niyati Bafna, Josef van Genabith, Cristina España-Bonet and Zdenêk Zabokrtský
In proceedings of the Conference on Computational Natural Language Learning (CoNLL 2022), pages 110-131, December 7-8, Abu Dhabi, UAE (hybrid), 2022.
[
Abstract
PDF
BibTeX
]
We present a novel method for unsupervised cognate/borrowing identification from monolingual corpora designed for low and extremely low resource scenarios, based on combining noisy semantic signals from joint bilingual spaces with orthographic cues modelling sound change. We apply our method to the North Indian dialect continuum, containing several dozens of dialects and languages spoken by more than 100 million people. Many of these languages are zero-resource and therefore natural language processing for them is non-existent. We first collect monolingual data for 26 Indic languages, 16 of which were previously zero-resource, and perform exploratory character, lexical and subword cross-lingual alignment experiments for the first time at this scale on this dialect continuum. We create bilingual evaluation lexicons against Hindi for 20 of the languages. We then apply our cognate identification method on the data, and show that our method outperforms both traditional orthography baselines as well as EM-style learnt edit distance matrices. To the best of our knowledge, this is the first work to combine traditional orthographic cues with noisy bilingual embeddings to tackle unsupervised cognate detection in a (truly) low-resource setup, showing that even noisy bilingual embeddings can act as good guides for this task. We release our multilingual dialect corpus, called HinDialect, as well as our scripts for evaluation data collection and cognate induction.
@InProceedings{BafnaEtal:CoNLL:2022,
author = {Niyati Bafna, Josef van Genabith, Cristina Espa{\~n}a-Bonet and Zden\v{e}k \v{Z}abokrtsk\'{y}},
title = "Combining Noisy Semantic Signals with Orthographic Cues: Cognate Induction for the Indic Dialect Continuum",
booktitle = "Proceedings of the 2022 Conference on Computational Natural Language Learning (CoNLL 2022)",
month = dec,
year = "2022",
address = "Abu Dhabi, UAE (hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.conll-1.9.pdf",
pages = "110--131"
}
Findings of the WMT 2022 Shared Task on Sign Language Translation
Mathias Müller and Ebling, Sarah and Avramidis, Eleftherios and Battisti, Alessia and Berger, Michèle, and Bowden, Richard
and Braffort, Annelies, and Camgöz, Necati Cihan and España-Bonet, Cristina and Grundkiewicz, Roman and Jiang, Zifan
and Koller, Oscar and Moryossef, Amit and Perrollaz, Regula and Reinhard, Sabine and Rios, Annette and Shterionov, Dimitar and
Sidler-Miserez, Sandra and Tissi, Katja and Van Landuyt, Davy.
In proceedings of the Seventh Conference on Machine Translation (WMT 2022), pages 744-772, December 7-8, Abu Dhabi, UAE (hybrid), 2022.
[
Abstract
PDF
BibTeX
]
This paper presents the results of the First WMT Shared Task on Sign Language Translation (WMT-SLT22). This shared task is concerned with automatic translation between signed and spoken languages. The task is novel in the sense that it requires processing visual information (such as video frames or human pose estimation) beyond the well-known paradigm of text-to-text machine translation (MT). The task featured two tracks, translating from Swiss German Sign Language (DSGS) to German and vice versa. Seven teams participated in this first edition of the task, all submitting to the DSGS-to-German track.
Besides a system ranking and system papers describing state-of-the-art techniques, this shared task makes the following scientific contributions: novel corpora, reproducible baseline systems and new protocols and software for human evaluation. Finally, the task also resulted in the first publicly available set of system outputs and human evaluation scores for sign language translation.
@InProceedings{mullerEtAl:WMT:2022,
author = {Mathias M\"uller and Ebling, Sarah and Avramidis, Eleftherios and Battisti, Alessia and Berger, Mich{\`e}le, and Bowden, Richard
and Braffort, Annelies, and Camg{\"o}z, Necati Cihan and Espa{\~n}a-Bonet, Cristina and Grundkiewicz, Roman and Jiang, Zifan
and Koller, Oscar and Moryossef, Amit and Perrollaz, Regula and Reinhard, Sabine and Rios, Annette and Shterionov, Dimitar and
Sidler-Miserez, Sandra and Tissi, Katja and Van Landuyt, Davy.},
title = "Findings of the {WMT} 2022 Shared Task on Sign Language Translation",
booktitle = {Proceedings of the Seventh Conference on Machine Translation},
key = {WMT 2022},
pages = {744--772},
year = {2022},
month = {December},
address = {Abu Dhabi, UAE (hybrid)},
publisher = {Association for Computational Linguistics}
}
DFKI-MLT at WMT-SLT22: Spatio-temporal Sign Language Representation and Translation.
Yasser Hamidullah, Josef van Genabith and Cristina España-Bonet
In proceedings of the Seventh Conference on Machine Translation (WMT 2022), pages 977-982, December 7-8, Abu Dhabi, UAE (hybrid), 2022.
[
Abstract
PDF
BibTeX
]
This paper describes the DFKI-MLT submission to the WMT-SLT 2022 sign language translation (SLT) task from Swiss German Sign Language (video) into German (text).
State-of-the-art techniques for SLT use a generic seq2seq architecture with customized input embeddings. Instead of word embeddings as used in textual machine translation, SLT systems use features extracted from video frames. Standard approaches often do not benefit from temporal features. In our participation, we present a system that learns spatio-temporal feature representations and translation in a single model, resulting in a real end-to-end architecture expected to better generalize to new data sets. Our best system achieved $5\pm1$ BLEU points on the development set, but the performance on the test dropped to 0.11±0.06 BLEU points.
@InProceedings{hamidullaEtAl:WMT:2022,
author = {Yasser Hamidullah, Josef van Genabith and Cristina Espa{\~n}a-Bonet},
title = "{DFKI-MLT at WMT-SLT22: Spatio-temporal Sign Language Representation and Translation.}",
booktitle = {Proceedings of the Seventh Conference on Machine Translation},
key = {WMT 2022},
pages = {977--982},
year = {2022},
month = {December},
address = {Abu Dhabi, UAE (hybrid)},
publisher = {Association for Computational Linguistics}
}
Towards Automated Sign Language Production: A Pipeline for Creating Inclusive Virtual Humans
Bernhard, Lucas and Nunnari, Fabrizio and Unger, Amelie and Bauerdiek, Judith and Dold, Christian and Hauck, Marcel and Stricker, Alexander and Baur, Tobias and Heimerl, Alexander and André, Elisabeth and Reinecker, Melissa and España-Bonet, Cristina and Hamidullah, Yasser and Busemann, Stephan and Gebhard, Patrick and Jäger, Corinna and Wecker, Sonja and Kossel, Yvonne and Müller, Henrik and Waldow, Kristoffer and Fuhrmann, Arnulph and Misiak, Martin and Wallach, Dieter
In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments (PETRA '22), pages 26-34. Association for Computing Machinery, New York, NY, USA.
[
Abstract
PDF
BibTeX
arXiv
]
In everyday life, Deaf People face barriers because information is often only available in spoken or written language. Producing sign language videos showing a human interpreter is often not feasible due to the amount of data required or because the information changes frequently. The ongoing AVASAG project addresses this issue by developing a 3D sign language avatar for the automatic translation of texts into sign language for public services. The avatar is trained using recordings of human interpreters translating text into sign language. For this purpose, we create a corpus with video and motion capture data and an annotation scheme that allows for real-time translation and subsequent correction without requiring to correct the animation frames manually. This paper presents the general translation pipeline focusing on innovative points, such as adjusting an existing annotation system to the specific requirements of sign language and making it usable to annotators from the Deaf communities.
@inproceedings{10.1145/3529190.3529202,
author = {Bernhard, Lucas and Nunnari, Fabrizio and Unger, Amelie and Bauerdiek, Judith and Dold, Christian and Hauck, Marcel and Stricker, Alexander and Baur, Tobias and Heimerl, Alexander and Andr\'{e}, Elisabeth and Reinecker, Melissa and Espa\~{n}a-Bonet, Cristina and Hamidullah, Yasser and Busemann, Stephan and Gebhard, Patrick and J\"{a}ger, Corinna and Wecker, Sonja and Kossel, Yvonne and M\"{u}ller, Henrik and Waldow, Kristoffer and Fuhrmann, Arnulph and Misiak, Martin and Wallach, Dieter},
title = {Towards Automated Sign Language Production: A Pipeline for Creating Inclusive Virtual Humans},
year = {2022},
isbn = {9781450396318},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3529190.3529202},
doi = {10.1145/3529190.3529202},
abstract = {In everyday life, Deaf People face barriers because information is often only available in spoken or written language. Producing sign language videos showing a human interpreter is often not feasible due to the amount of data required or because the information changes frequently. The ongoing AVASAG project addresses this issue by developing a 3D sign language avatar for the automatic translation of texts into sign language for public services. The avatar is trained using recordings of human interpreters translating text into sign language. For this purpose, we create a corpus with video and motion capture data and an annotation scheme that allows for real-time translation and subsequent correction without requiring to correct the animation frames manually. This paper presents the general translation pipeline focusing on innovative points, such as adjusting an existing annotation system to the specific requirements of sign language and making it usable to annotators from the Deaf communities.},
booktitle = {Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments},
pages = {26--35},
keywords = {sign language production, automatic translation., annotation, motion capture, corpus},
location = {Corfu, Greece},
series = {PETRA '22}
}
Multilingual Neural Machine Translation
Cristina España-Bonet
Invited talk at the 11th Advanced Summer School on NLP (IASNLP-2022), IIIT Hyderabad, India, 23rd June 2022.
Towards Debiasing Translation Artifacts
Koel Dutta Chowdhury, Rricha Jalota, Cristina España-Bonet and Josef van Genabith
Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2022), pages 3983-3991, July 10-15, Seattle, 2022.
[
Abstract
PDF
BibTeX
arXiv
]
Cross-lingual natural language processing relies on translation, either by humans or machines, at different levels, from translating training data to translating test sets. However, compared to original texts in the same language, translations possess distinct qualities referred to as translationese. Previous research has shown that these translation artifacts influence the performance of a variety of cross-lingual tasks. In this work, we propose a novel approach to reducing translationese by extending an established bias-removal technique. We use the Iterative Null-space Projection (INLP) algorithm, and show by measuring classification accuracy before and after debiasing, that translationese is reduced at both sentence and word level. We evaluate the utility of debiasing translationese on a natural language inference (NLI) task, and show that by reducing this bias, NLI accuracy improves. To the best of our knowledge, this is the first study to debias translationese as represented in latent embedding space.
@InProceedings{DuttaEtal:NAACL:2022,
author = {Dutta Chowdhury, Koel and Jalota, Rricha and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef},
title = "Towards Debiasing Translation Artifacts",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2022)",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.292",
pages = "3983--3991"
}
Exploiting Social Media Content for Self-Supervised Style Transfer
Dana Ruiter, Thomas Kleinbauer, Cristina España-Bonet, Dietrich Klakow, Josef van Genabith
10th International Workshop on Natural Language Processing for Social Media (SocialNLP2022), pages 11-23, July 14-15, Seattle, USA, 2022.
[
Abstract
PDF
BibTeX
arXiv
]
Recent research on style transfer takes inspiration from unsupervised neural machine translation (UNMT), learning from large amounts of non-parallel data by exploiting cycle consistency loss, back-translation, and denoising autoencoders. By contrast, the use of self-supervised NMT (SSNMT), which leverages (near) parallel instances hidden in non-parallel data more efficiently than UNMT, has not yet been explored for style transfer. In this paper we present a novel Self-Supervised Style Transfer (3ST) model, which augments SSNMT with UNMT methods in order to identify and efficiently exploit supervisory signals in non-parallel social media posts. We compare 3ST with state-of-the-art (SOTA) style transfer models across civil rephrasing, formality and polarity tasks. We show that 3ST is able to balance the three major objectives (fluency, content preservation, attribute transfer accuracy) the best, outperforming SOTA models on averaged performance across their tested tasks in automatic and human evaluation.
@InProceedings{RuiterEtal:2022,
author = {Dana Ruiter, Thomas Kleinbauer, Cristina Espa{\~n}a-Bonet, Josef van Genabith, Dietrich Klakow},
title = "{Exploiting Social Media Content for Self-Supervised Style Transfer}",
booktitle = {Proceedings of the 10th International Workshop on Natural Language Processing for Social Media},
year = 2022,
month = July,
address = "Seattle, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.socialnlp-1.2.pdf",
pages = {11--23}
}
Low-resource Natural Language Processing (or a Bit of it!)
Cristina España-Bonet
Invited talk at the 3rd AfricaNLP workshop collocated with ICLR, 29th April 2022.
[
Slides
Abstract
]
Under this very generic title I will summarise some work in our group related to embeddings, machine translation and evaluation that has been done for languages from Sub-Saharan Africa. I will start by defining a low-resource setting and we will see how, in this case, the (language-dependent) curation of the data is crucial for some tasks. Afterwards I will focus on neural machine translation (NMT) and compare several approaches when only a limited amount of parallel data is available. Using one of the models as example, self-supervised NMT, we will discuss the evaluation of such models to see that, in low-resource settings, not only trainings but also evaluations are a challenge.
2021
Low-Resource NLP: Multilinguality and Machine Translation
Cristina España-Bonet
LT-BRIDGE Webinar Series, Summer 2021.
[
Topics
Session 1
YoutubeS1
Session 2
YoutubeS2
Session 3
YoutubeS3
Session 4
YoutubeS4
Session 5
YoutubeS5
]
Session 1
- Motivation
Session 2
- Recap on LR-NLP
- Cross-lingual Embeddings
- Unsupervised Neural Machine Translation
Session 3
- Recap on CL-WE and UNMT
- Neural Machine Translation
- Low-Resource Setting for NMT
- Multilingual Neural Machine Translation
Session 4
- Recap on Multilingual NMT
- Self-Supervised Neural Machine Translation
- Sentence Embeddings with LASER
- Pretrained Language Models and Seq2Seq systems
Session 5
- State-of-the-art: WMT Evaluations
- Multilingual Low-Resource Translation for Indo-European Languages @WMT21
Findings of the 2021 Conference on Machine Translation (WMT21)
Farhad Akhbardeh, Arkady Arkhangorodsky, Magdalena Biesialska, Ondrej Bojar, Rajen Chatterjee, Vishrav Chaudhary, Marta R. Costa-jussa, Cristina España-Bonet, Angela Fan, Christian Federmann, Markus Freitag, Yvette Graham, Roman Grundkiewicz, Barry Haddow, Leonie Harter, Kenneth Heafield, Christopher Homan, Matthias Huck, Kwabena Amponsah-Kaakyire, Jungo Kasai, Daniel Khashabi, Kevin Knight, Tom Kocmi, Philipp Koehn, Nicholas Lourie, Christof Monz, Makoto Morishita, Masaaki Nagata, Ajay Nagesh, Toshiaki Nakazawa, Matteo Negri, Santanu Pal, Allahsera Auguste Tapo, Marco Turchi, Valentin Vydrin and Marcos Zampieri
In Proceedings of the Sixth Conference on Machine Translation (WMT), pages 1-93, Punta Cana (online), November 2021.
[
Abstract
PDF
BibTeX
]
This paper presents the results of the news translation task, the multilingual low-resource translation for Indo-European languages, the triangular translation task, and the automatic post-editing task organised as part of the Conference on Machine Translation (WMT) 2021. In the news task, participants were asked to build machine translation systems for any of 10 language pairs, to be evaluated on test sets consisting mainly of news stories. The task was also opened up to additional test suites to probe specific aspects of translation. In the Similar Language Translation (SLT) task, participants were asked to develop systems to translate between pairs of similar languages from the Dravidian and Romance family as well as French to two similar low-resource Manding languages (Bambara and Maninka). In the Triangular MT translation task, participants were asked to build a Russian to Chinese translator, given parallel data in Russian-Chinese, Russian-English and English-Chinese. In the multilingual low-resource translation for Indo-European languages task, participants built multilingual systems to translate among Romance and North-Germanic languages. The task was designed to deal with the translation of documents in the cultural heritage domain for relatively low-resourced languages. In the automatic post-editing (APE) task, participants were asked to develop systems capable to correct the errors made by an unknown machine translation systems.
@InProceedings{wmt:2021,
author = {Akhbardeh, Farhad and Arkhangorodsky, Arkady and Biesialska, Magdalena and Bojar, Ond},ej and Chatterjee, Rajen and Chaudhary, Vishrav and Costa-jussa, Marta R. and
Espa{\~n}a-Bonet, Cristina and Fan, Angela and Federmann, Christian and Freitag, Markus and Graham, Yvette and Grundkiewicz, Roman and Haddow, Roman and Harter, Leonie and Heafield,
Kenneth and
title = "Findings of the 2021 Conference on Machine Translation (WMT21)",
booktitle = "Proceedings of the Sixth Conference on Machine Translation (WMT)",
month = nov,
year = "2021",
address = "Punta Cana (Online)",
publisher = "Association for Computational Linguistics",
url = "http://statmt.org/wmt21/pdf/2021.wmt-1.1.pdf",
pages = "1--93"
}
Comparing Feature-Engineering and Feature-Learning Approaches for Multilingual Translationese Classification
Daria Pylypenko, Kwabena Amponsah-Kaakyire, Koel Dutta Chowdhury, Josef van Genabith and Cristina España-Bonet
In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP 2021), pages 8596-8611, Punta Cana (online), November 2021.
[
Abstract
PDF
BibTeX
arXiv
]
Traditional hand-crafted linguistically-informed features have often been used for distinguishing between translated and original non-translated texts. By contrast, to date, neural architectures without manual feature engineering have been less explored for this task. In this work, we (i) compare the traditional feature-engineering-based approach to the feature-learning-based one and (ii) analyse the neural architectures in order to investigate how well the hand-crafted features explain the variance in the neural models' predictions. We use pre-trained neural word embeddings, as well as several end-to-end neural architectures in both monolingual and multilingual settings and compare them to feature-engineering-based SVM classifiers. We show that (i) neural architectures outperform other approaches by more than 20 accuracy points, with the BERT-based model performing the best in both the monolingual and multilingual settings; (iii) while many individual hand-crafted translationese features correlate with neural model predictions, feature importance analysis shows that the most important features for neural and classical architectures differ; and (iii) our multilingual experiments provide empirical evidence for translationese universals across languages.
@InProceedings{PylypenkoEtal:EMNLP:2021,
author = {Pylypenko, Daria and Amponsah-Kaakyire, Kwabena and Dutta Chowdhury, Koel and van Genabith, Josef and Espa{\~n}a-Bonet, Cristina},
title = "Comparing Feature-Engineering and Feature-Learning Approaches for Multilingual Translationese Classification",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP21)",
month = nov,
year = "2021",
address = "Punta Cana (Online)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.676.pdf",
pages = "8596--8611"
}
Tracing Source Language Interference in Translation with Graph-Isomorphism Measures
Koel Dutta Chowdhury, Cristina España-Bonet and Josef van Genabith
Proceedings of Recent Advances in Natural Language Processing (RANLP 2021), pages 380-390, September 1-3, Virtual, 2021.
[
Abstract
PDF
BibTeX
arXiv
]
Previous research has used linguistic features to show that translations exhibit traces of source language interference and that phylogenetic trees between languages can be reconstructed from the results of translations into the same language. Recent research has has been shown that instances of translationese (source language interference) can even be detected in embedding spaces, comparing embeddings spaces of original language data with embedding spaces resulting from translations into the same language, using a simple Eigenvector-based divergence from isomorphism measure. To date it remains an open question whether alternative graph-isomorphism measures can produce better results. In this paper, we (i) explore Gromov-Hausdorff distance, (ii) present a novel spectral version of the Eigenvector-based method, and (iii) evaluate all approaches against a broad linguistic typological database (URIEL). We show that language distances resulting from our spectral isomorphism approaches can reproduce genetic trees at par with previous work without requiring any explicit linguistic information and that the results can be extended to non-Indo-European languages. Finally, we show that the methods are robust under a variety of modeling conditions.
@InProceedings{DuttaEtal:RANLP:2021,
author = {Dutta Chowdhury, Koel and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef},
title = "Tracing Source Language Interference in Translation with Graph-Isomorphism Measures",
booktitle = "Proceedings of the International Conference Recent Advances in Natural Language Processing, {RANLP} 2021",
editor = "Mitkov, Ruslan and Angelova, Galia",
month = sep,
year = "2021",
address = "Varna, Bulgaria",
publisher = "INCOMA Ltd.",
doi = "https://doi.org/10.26615/978-954-452-072-4\_044"
pages = "380--390"
}
Integrating Unsupervised Data Generation into Self-Supervised Neural Machine Translation for Low-Resource Languages
Dana Ruiter, Dietrich Klakow, Josef van Genabith, Cristina España-Bonet
The 18th biennial conference of the International Association of Machine Translation, MT Summit XVIII, Vol 1: MT Research Track, pages 76-91, August 16-20, Virtual, 2021.
[
Abstract
PDF
BibTeX
arXiv
]
For most language combinations, parallel data is either scarce or simply unavailable. To address this, unsupervised machine translation (UMT) exploits large amounts of monolingual data by using synthetic data generation techniques such as back-translation and noising, while self-supervised NMT (SSNMT) identifies parallel sentences in smaller comparable data and trains on them. To date, the inclusion of UMT data generation techniques in SSNMT has not been investigated. We show that including UMT techniques into SSNMT significantly outperforms SSNMT and UMT on all tested language pairs, with improvements of up to +4.3 BLEU, +50.8 BLEU, +51.5 over SSNMT, statistical UMT and hybrid UMT, respectively, on Afrikaans to English. We further show that the combination of multilingual denoising autoencoding, SSNMT with backtranslation and bilingual finetuning enables us to learn machine translation even for distant language pairs for which only small amounts of monolingual data are available, e.g. yielding BLEU scores of 11.6 (English to Swahili).
@InProceedings{RuiterEtal:2021,
author = {Dana Ruiter, Dietrich Klakow, Josef van Genabith, Cristina Espa{\~n}a-Bonet},
title = "{Integrating Unsupervised Data Generation into Self-Supervised Neural Machine Translation for Low-Resource Languages}",
booktitle = {Proceedings of the 18th biennial conference of the International Association of Machine Translation, MT Summit XVIII, Vol 1: MT Research Track},
year = 2021,
month = August,
address = "Virtual",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2021.mtsummit-research.7",
pages = {76--91}
}
The Effect of Domain and Diacritics in Yorúbà-English Neural Machine Translation
David I. Adelani, Dana Ruiter, Jesujoba O. Alabi, Damilola Adebonojo, Adesina Ayeni, Mofe Adeyemi, Ayodele Awokoya, Cristina España-Bonet
The 18th biennial conference of the International Association of Machine Translation, MT Summit XVIII, Vol 1: MT Research Track, pages 62-75, August 16-20, Virtual, 2021.
[
Abstract
PDF
BibTeX
arXiv
]
Massively multilingual machine translation (MT) has shown impressive capabilities, including zero and few-shot translation between low-resource language pairs. However, these models are often evaluated on high-resource languages with the assumption that they generalize to low-resource ones. The difficulty of evaluating MT models on low-resource pairs is often due to lack of standardized evaluation datasets. In this paper, we present MENYO-20k, the first multi-domain parallel corpus with a special focus on clean orthography for Yorúbà-English with standardized train-test splits for benchmarking. We provide several neural MT benchmarks and compare them to the performance of popular pre-trained (massively multilingual) MT models both for the heterogeneous test set and its subdomains. Since these pre-trained models use huge amounts of data with uncertain quality, we also analyze the effect of diacritics, a major characteristic of Yorúbà, in the training data. We investigate how and when this training condition affects the final quality and intelligibility of a translation. Our models outperform massively multilingual models such as Google (+8.7 BLEU) and Facebook M2M (+9.1 BLEU) when translating to Yorúbà, setting a high quality benchmark for future research.
@InProceedings{AdelaniEtal:2021,
author = {David I. Adelani, Dana Ruiter, Jesujoba O. Alabi, Damilola Adebonojo, Adesina Ayeni, Mofe Adeyemi, Ayodele Awokoya, Cristina Espa{\~n}a-Bonet},
title = "{The Effect of Domain and Diacritics in Yor\`ub\'a--English Neural Machine Translation}",
booktitle = {Proceedings of the 18th biennial conference of the International Association of Machine Translation, MT Summit XVIII, Vol 1: MT Research Track},
year = 2021,
month = August,
address = "Virtual",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2021.mtsummit-research.6",
pages = {62--75}
}
AVASAG: A German Sign Language Translation System for Public Services
Fabrizio Nunnari, Judith Bauerdiek, Lucas Bernhard, Cristina España-Bonet, Corinna Jäger, Amelie Unger, Kristoffer Waldow, Sonja Wecker, Elisabeth André, Stephan Busemann, Christian Dold, Arnulph Fuhrmann, Patrick Gebhard, Yasser Hamidullah, Marcel Hauck, Yvonne Kossel, Martin Misiak, Dieter Wallach, Alexander Stricker
Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (AT4SSL), pages 43-48, August 16-20, Virtual, 2021.
[
Abstract
PDF
BibTeX
]
This paper presents an overview of AVASAG; an ongoing applied-research project developing a text-to-sign-language translation system for public services. We describe the scientific innovation points (geometry-based SL-description, 3D animation and video corpus, simplified annotation scheme, motion capture strategy) and the overall translation pipeline.
@InProceedings{NunnariEtal:2021,
title = "{AVASAG}: A {G}erman {S}ign {L}anguage Translation System for Public Services",
author = {Nunnari, Fabrizio and
Bauerdiek, Judith and
Bernhard, Lucas and
Espa{\~n}a-Bonet, Cristina and
J{\"a}ger, Corinna and
Unger, Amelie and
Waldow, Kristoffer and
Wecker, Sonja and
Andr{\'e}, Elisabeth and
Busemann, Stephan and
Dold, Christian and
Fuhrmann, Arnulph and
Gebhard, Patrick and
Hamidullah, Yasser and
Hauck, Marcel and
Kossel, Yvonne and
Misiak, Martin and
Wallach, Dieter and
Stricker, Alexander},
booktitle = "Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (AT4SSL)",
month = aug,
year = "2021",
address = "Virtual",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2021.mtsummit-at4ssl.5",
pages = "43--48"
}
A Data Augmentation Approach for Sign-language-to-text Translation In-the-wild (BEST POSTER AWARD)
Fabrizio Nunnari, Cristina España-Bonet and Eleftherios Avramidis
Proceedings of the 3rd Conference on Language, Data and Knowledge (LDK2021), Open Access Series in Informatics (OASIcs), Vol. 93, pages 36:1-36:8, September 2021.
[
Abstract
PDF
Poster
BibTeX
arXiv
]
In this paper, we describe the current main approaches to sign language translation which use deep neural networks with videos as input and text as output. We highlight that, under our point of view, their main weakness is the lack of generalization in daily life contexts. Our goal is to build a state-of-the-art system for the automatic interpretation of sign language in unpredictable video framing conditions. Our main contribution is the shift from image features to landmark positions in order to diminish the size of the input data and facilitate the combination of data augmentation techniques for landmarks. We describe the set of hypotheses to build such a system and the list of experiments that will lead us to their verification.
@InProceedings{NunnariEtal:LDK:2021,
author = {Nunnari, Fabrizio and Espa\~{n}a-Bonet, Cristina and Avramidis, Eleftherios},
title = {{A Data Augmentation Approach for Sign-Language-To-Text Translation In-The-Wild}},
booktitle = {3rd Conference on Language, Data and Knowledge (LDK 2021)},
pages = {36:1--36:8},
series = {Open Access Series in Informatics (OASIcs)},
ISBN = {978-3-95977-199-3},
ISSN = {2190-6807},
year = {2021},
volume = {93},
editor = {Gromann, Dagmar and S\'{e}rasset, Gilles and Declerck, Thierry and McCrae, John P. and Gracia, Jorge and Bosque-Gil, Julia and Bobillo, Fernando and Heinisch, Barbara},
publisher = {Schloss Dagstuhl -- Leibniz-Zentrum f{\"u}r Informatik},
address = {Dagstuhl, Germany},
URL = {https://drops.dagstuhl.de/opus/volltexte/2021/14572},
URN = {urn:nbn:de:0030-drops-145728},
doi = {10.4230/OASIcs.LDK.2021.36},
annote = {Keywords: sing language, video recognition, end-to-end translation, data augmentation}
}
Do not Rely on Relay Translations: Multilingual Parallel Direct Europarl
Kwabena Amponsah-Kaakyire, Daria Pylypenko, Cristina España-Bonet and Josef van Genabith
Proceedings of the Workshop on Modelling Translation: Translatology in the Digital Age (MoTra21), pages 1-7, Iceland (online), May 2021.
[
Abstract
PDF
BibTeX
arXiv
]
Translationese data is a scarce and valuable resource. Traditionally, the proceedings of the European Parliament have been used for studying translationese phenomena since their metadata allows to distinguish between original and translated texts. However, translations are not always direct and we hypothesise that a pivot (also called "relay") language might alter the conclusions on translationese effects. In this work, we (i) isolate translations that have been done without an intermediate language in the Europarl proceedings from those that might have used a pivot language, and (ii) build comparable and parallel corpora with data aligned across multiple languages that therefore can be used for both machine translation and translation studies.
@InProceedings{AmposahEtal:MOTRA:2021,
author = {Amponsah-Kaakyire, Kwabena and Pylypenko, Daria and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef},
title = "Do not Rely on Relay Translations: Multilingual Parallel Direct Europarl",
booktitle = "Proceedings of the Workshop on Modelling Translation: Translatology in the Digital Age (MoTra21)",
month = may,
year = "2021",
address = "Iceland (Online)",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.motra-1.1",
pages = "1--7"
}
MENYO-20k: A Multi-domain English-Yorúbà Corpus for Machine Translation
David I. Adelani, Dana Ruiter, Jesujoba O. Alabi, Damilola Adebonojo, Adesina Ayeni, Mofe Adeyemi, Ayodele Awokoya, Cristina España-Bonet
arXiv pre-print 2103.08647, March 2021. Accepted to the AfricaNLP 2021 Workshop.
[
Abstract
PDF
BibTeX
arXiv
]
Massively multilingual machine translation (MT) has shown impressive capabilities, including zero and few-shot translation between low-resource language pairs. However, these models are often evaluated on high-resource languages with the assumption that they generalize to low-resource ones. The difficulty of evaluating MT models on low-resource pairs is often due the lack of standardized evaluation datasets. In this paper, we present MENYO-20k, the first multi-domain parallel corpus for the low-resource Yorúbà-English (yo-en) language pair with standardized train-test splits for benchmarking. We provide several neural MT (NMT) benchmarks on this dataset and compare to the performance of popular pre-trained (massively multilingual) MT models, showing that, in almost all cases, our simple benchmarks outperform the pre-trained MT models. A major gain of BLEU +9.9 and +8.6 (en2yo) is achieved in comparison to Facebook's M2M-100 and Google multilingual NMT respectively when we use MENYO-20k to fine-tune generic models.
@InProceedings{AdelaniEtal:2020,
author = {David I. Adelani, Dana Ruiter, Jesujoba O. Alabi, Damilola Adebonojo, Adesina Ayeni, Mofe Adeyemi, Ayodele Awokoya, Cristina Espa{\~n}a-Bonet},
title = "{MENYO-20k: A Multi-domain English-Yor\`ub\'a Corpus for Machine Translation}",
journal = {arXiv e-prints},
year = 2021,
month = April,
pages = {1--12},
archivePrefix = {arXiv},
eprint = {2103.08647},
primaryClass = {cs.CL}
}
Multilingual Sentence Embeddings in/for/and Neural Machine Translation
Cristina España-Bonet
Talk at the Recent Advances in Machine Translation Symposium, 18th March 2021.
[
Slides
Abstract
]
Neural machine translation (NMT) experienced a big boost in quality with the emergence of Transformer models. Almost concurrently, Transformer models were successfully used to obtain contextualised embeddings and several extensions to the base model have achieved high quality sentence embeddings. In this talk I will outline synergies between sentence embeddings and neural machine translation with special focus into self-supervised NMT, a new architecture that uses its own internal embeddings for data selection during training. I will also describe how (multilingual) sentence embeddings are being used to improve the performance for low-resourced languages when used in combination with (multilingual) NMT.
2020
Understanding Translationese in Multi-view Embedding Spaces
Koel Dutta Chowdhury, Cristina España-Bonet and Josef van Genabith
Proceedings of the 28th International Conference on Computational Linguistics (COLING 2020), pages 6056-6062, December 2020.
[
Abstract
PDF
BibTeX
arXiv
]
The term translationese refers to systematic differences between translations and text originally authored in the target language of the translation (in the same genre and style). In this paper, we use departures from isomorphism between embedding-based vector spaces from translations and originally authored data to estimate phylogenetic language family relations induced from single target language translation from multiple source languages. We explore multi-view embedding spaces based on words, part-of-speech, semantic tags, and synsets, to capture lexical, morphological and semantic aspects of translationese and to investigate the impact of topic on the data. Our results show that (i) language family relationships can be inferred from the monolingual embedding data, providing evidence for shining-through (source language interference) translationese effects in the data and (ii) that, perhaps surprisingly, even delexicalised embeddings exhibit significant source language interference, indicating that the lexicalised results are due to possible differences in topic between original and translated texts.
@InProceedings{DuttaEtal:COLING:2020,
author = {Dutta Chowdhury, Koel and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef},
title = "Understanding Translationese in Multi-view Embedding Spaces",
booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
month = dec,
year = "2020",
address = "Barcelona, Catalonia (Online)",
publisher = "International Committee on Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.coling-main.532",
pages = "6056--6062"
}
Self-Induced Curriculum Learning in Self-Supervised Neural Machine Translation
Dana Ruiter, Josef van Genabith and Cristina España-Bonet
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2560-2571, November 2020.
[
Abstract
PDF
BibTeX
]
Self-supervised neural machine translation (SSNMT) jointly learns to identify and select suitable training data from comparable (rather than parallel) corpora and to translate, in a way that the two tasks support each other in a virtuous circle. In this study, we provide an in-depth analysis of the sampling choices the SSNMT model makes during training. We show how, without it having been told to do so, the model self-selects samples of increasing (i) complexity and (ii) task-relevance in combination with (iii) performing a denoising curriculum. We observe that the dynamics of the mutual-supervision signals of both system internal representation types are vital for the extraction and translation performance. We show that in terms of the Gunning-Fog readability index, SSNMT starts extracting and learning from Wikipedia data suitable for high school students and quickly moves towards content suitable for first year undergraduate students.
@InProceedings{ruiterEtAl:EMNLP:2020,
author = {Dana Ruiter and Josef van Genabith and Cristina Espa\~na-Bonet},
title = "{Self-Induced Curriculum Learning in Self-Supervised Neural Machine Translation}",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.202",
doi = "10.18653/v1/2020.emnlp-main.202",
pages = "2560--2571"
}
Statistical Machine Translation: Main Components
Cristina España-Bonet
Invited talk at the 1r Congreso Internacional de Procesamiento de Lenguaje Natural para Lenguas Indígenas, Morelia, México, 5th November 2020.
Some Aspects of Linguistic Diversity in Europe and Africa
Cristina España-Bonet
Invited talk at the SPARC International Symposium on Mahatma Gandhi and Linguistic Diversity, 23rd September 2020.
Query or Document Translation for Academic Search — What's the real Difference?
Vivien Petras, Andreas Lüschow, Roland Ramthun, Juliane Stiller, Cristina España-Bonet and Sophie Henning
Experimental IR Meets Multilinguality, Multimodality, and Interaction, 11th International Conference of the CLEF Association, CLEF
2020, Thessaloniki, Greece, September 22-25, 2020. Lecture Notes in Computer Science, Vol. 12260, pages 28-42, Springer.
[
Abstract
PDF
BibTeX
]
We compare query and document translation from and to English, French, German and Spanish for multilingual retrieval in an academic search portal: PubPsych. Both query and document translation improve the retrieval performance of the system with document translation providing better results. We show how performance inversely correlates with the amount of available original language documents. The more documents already available in a language, the fewer improvements can be observed. Retrieval performance with English as a source language does not improve with translation as most documents already contained English-language content in our text collection. The large-scale evaluation study is based on a corpus of more than 1 M metadata documents and 50 real queries in English, French, German and Spanish taken from the query log files of the portal.
@InProceedings{petrasEtAl:CLEF:2020,
author = {Vivien Petras, Andreas L\"uschow, Roland Ramthun, Juliane Stiller, Cristina Espa{\~n}a-Bonet and Sophie Henning},
title = "{Query or Document Translation for Academic Search -- What's the real Difference?}",
booktitle = {Experimental {IR} Meets Multilinguality, Multimodality, and Interaction
- 11th International Conference of the {CLEF} Association, {CLEF}
2020, Thessaloniki, Greece, September 22-25, 2020, Proceedings},
series = {Lecture Notes in Computer Science},
volume = {12260},
pages = {28--42},
publisher = {Springer},
year = {2020},
doi = {10.1007/978-3-030-58219-7\_3},
key = {CLEF 2020},
year = {2020},
month = {September},
address = {Thessaloniki, Greece},
}
How Human is Machine Translationese? Comparing Human and Machine Translations of Text and Speech
Yuri Bizzoni, Tom S Juzek, Cristina España-Bonet, Koel Dutta Chowdhury, Josef van Genabith and Elke Teich
Proceedings of the 17th International Workshop on Spoken Language Translation (IWSLT), pages 280-290, Seattle, WA, United States, July 2020.
[
Abstract
PDF
BibTeX
arXiv
]
Translationese is a phenomenon present in human translations, simultaneous interpreting, and even machine translations. Some translationese features tend to appear in simultaneous interpreting with higher frequency than in human text translation, but the reasons for this are unclear. This study analyzes translationese patterns in translation, interpreting, and machine translation outputs in order to explore possible reasons. In our analysis we (i) detail two non-invasive ways of detecting translationese and (ii) compare translationese across human and machine translations from text and speech. We find that machine translation shows traces of translationese, but does not reproduce the patterns found in human translation, offering support to the hypothesis that such patterns are due to the model (human vs. machine) rather than to the data (written vs. spoken).
@InProceedings{BizzoniEtal:IWSLT:2020,
author = {Bizzoni, Yuri and Juzek, Tom S and Espa{\~n}a-Bonet, Cristina and Dutta Chowdhury, Koel and van Genabith, Josef and Teich, Elke},
title = "How Human is Machine Translationese? Comparing Human and Machine Translations of Text and Speech",
booktitle = "Proceedings of the 17th International Conference on Spoken Language Translation",
month = jul,
year = "2020",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.iwslt-1.34",
pages = "280--290"
}
Tailoring and Evaluating the Wikipedia for in-Domain Comparable Corpora Extraction
Cristina España-Bonet, Alberto Barrón-Cedeño, Lluís Màrquez
arXiv pre-print 2005.01177, May 2020.
[
Abstract
PDF
BibTeX
arXiv
]
We propose an automatic language-independent graph-based method to build à-la-carte article collections on user-defined domains from the Wikipedia. The core model is based on the exploration of the encyclopaedia's category graph and can produce both monolingual and multilingual comparable collections. We run thorough experiments to assess the quality of the obtained corpora in 10 languages and 743 domains. According to an extensive manual evaluation, our graph-based model outperforms a retrieval-based approach and reaches an average precision of 84% on in-domain articles. As manual evaluations are costly, we introduce the concept of "domainness" and design several automatic metrics to account for the quality of the collections. Our best metric for domainness shows a strong correlation with the human-judged precision, representing a reasonable automatic alternative to assess the quality of domain-specific corpora. We release the WikiTailor toolkit with the implementation of the extraction methods, the evaluation measures and several utilities. WikiTailor makes obtaining multilingual in-domain data from the Wikipedia easy.
@InProceedings{EspanaBonetEtal:2020,
author = {{Espa{\~n}a-Bonet}, Cristina and {Barr\'on-Cede{\~n}o}, Alberto and {M\`arquez}, Llu\'{i}s},
title = "{Tailoring and Evaluating the Wikipedia for in-Domain Comparable Corpora Extraction}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language, Computer Science - Information Retrieval},
year = 2020,
month = may,
pages = {1--26},
archivePrefix = {arXiv},
eprint = {2005.01177},
primaryClass = {cs.CL}
}
Multilingual and Interlingual Semantic Representations for Natural Language Processing: A Brief Introduction
Marta R. Costa-jussà, Cristina España-Bonet, Pascale Fung and Noah A. Smith
Special Issue of Computational Linguistics: Multilingual and Interlingual Semantic Representations for Natural Language Processing, pages 1-8, March 2020
[
Abstract
PDF
BibTeX
]
We introduce the Computational Linguistics special issue on Multilingual and Interlingual Semantic Representations for Natural Language Processing. We situate the special issue's five articles in the context of our fast-changing field, explaining our motivation for this project. We offer a brief summary of the work in the issue, which includes developments on lexical and sentential semantic representations, from symbolic and neural perspectives.
@article{ruizEtal:2020,
title = "Multilingual and Interlingual Semantic Representations for Natural Language Processing: A Brief Introduction",
author = "Costa-juss{\`a}, Marta and Espa{\~n}a-Bonet, Cristina and Fung, Pascale and Smith, Noah A.",
publisher = {MIT Press},
address = {Cambridge, MA, USA},
journal = {Computational Linguistics},
month = mar,
year = "2020",
doi = "10.1162/COLI_a_00373",
pages = "1--8"
}
Massive vs. Curated Embeddings for Low-Resourced Languages: the Case of Yorùbá and Twi
Jesujoba O. Alabi, Kwabena Amponsah-Kaakyire, David I. Adelani and Cristina España-Bonet
Proceedings of the Twelfth International Conference on Language Resources and Evaluation (LREC 2020), pages 2754-2762 , Marseille, France, May 2020.
[
Abstract
PDF
BibTeX
]
The success of several architectures to learn semantic representations from unannotated text and the availability of these kind of texts in online multilingual resources such as Wikipedia has facilitated the massive and automatic creation of resources for multiple languages. The evaluation of such resources is usually done for the high-resourced languages, where one has a smorgasbord of tasks and test sets to evaluate on. For low-resourced languages, the evaluation is more difficult and normally ignored, with the hope that the impressive capability of deep learning architectures to learn (multilingual) representations in the high-resourced setting holds in the low-resourced setting too.
In this paper we focus on two African languages, Yorùbá and Twi, and compare the word embeddings obtained in this way, with word embeddings obtained from curated corpora and a language-dependent processing. We analyse the noise in the publicly available corpora, collect high quality and noisy data for the two languages and quantify the improvements that depend not only on the amount of data but on the quality too. We also use different architectures that learn word representations both from surface forms and characters to further exploit all the available information which showed to be important for these languages. For the evaluation, we manually translate the wordsim-353 word pairs dataset from English into Yorùbá and Twi.
We extend the analysis to contextual word embeddings and evaluate multilingual BERT on a named entity recognition task. For this, we annotate with named entities the Global Voices corpus for Yorùbá. As output of the work, we provide corpora, embeddings and the test suits for both languages.
@inproceedings{alabiEtal:2020:LREC,
title = "Massive vs. Curated Embeddings for Low-Resourced Languages: the Case of Yor\`ub\'a and Twi",
author = "Jesujoba O. Alabi, Kwabena Amponsah-Kaakyire, David I. Adelani and Cristina Espa{\~n}a-Bonet",
booktitle = "Proceedings of the Twelfth International Conference on Language Resources and Evaluation (LREC 2020)",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association (ELRA)",
url = "https://www.aclweb.org/anthology/2020.lrec-1.335/",
doi = "",
pages = "2754--2762"
}
GeBioToolkit: Automatic Extraction of Gender-Balanced Multilingual Corpus of Wikipedia Biographies
Marta R. Costa-jussà, Pau Li Lin and Cristina España-Bonet
Proceedings of the Twelfth International Conference on Language Resources and Evaluation (LREC 2020), pages 4081-4088, Marseille, France, May 2020.
[
Abstract
PDF
BibTeX
]
We introduce GeBioToolkit, a tool for extracting multilingual parallel corpora at sentence level, with document and gender information from Wikipedia biographies. Despite the gender inequalities present in Wikipedia, the toolkit has been designed to extract corpus balanced in gender. While our toolkit is customizable to any number of languages (and to other domains than biographical entries), in this work we present a corpus of 2,000 sentences in English, Spanish and Catalan, which has been post-edited by native speakers to become a high-quality dataset for machine translation evaluation. While GeBioCorpus aims at being one of the first non-synthetic gender-balanced test datasets, GeBioToolkit aims at paving the path to standardize procedures to produce gender-balanced datasets.
@inproceedings{ruizEtal:2020:LREC,
title = "GeBioToolkit: Automatic Extraction of Gender-Balanced Multilingual Corpus of Wikipedia Biographies",
author = "Costa-juss{\`a}, Marta and Li Lin, Pau and Espa{\~n}a-Bonet, Cristina",
booktitle = "Proceedings of the Twelfth International Conference on Language Resources and Evaluation (LREC 2020)",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association (ELRA)",
url = "https://www.aclweb.org/anthology/2020.lrec-1.502/",
doi = "",
pages = "4081--4088"
}
2019
Analysing Coreference in Transformer Outputs
Ekaterina Lapshinova-Koltunski, Cristina España-Bonet and Josef van Genabith
Proceedings of the Fourth Workshop on Discourse in Machine Translation (DiscoMT 2019), pages 1-12, Hong Kong, November 2019.
[
Abstract
PDF
BibTeX
]
We analyse coreference phenomena in three neural machine translation systems trained with different data settings with or without access to explicit intra- and cross-sentential anaphoric information. We compare system performance on two different genres: news and TED talks. To do this, we manually annotate (the possibly incorrect) coreference chains in the MT outputs and evaluate the coreference chain translations. We define an error typology that aims to go further than pronoun translation adequacy and includes types such as incorrect word selection or missing words. The features of coreference chains in automatic translations are also compared to those of the source texts and human translations. The analysis shows stronger potential translationese effects in machine translated outputs than in human translations.
@inproceedings{lapshinovaEtal:2019:DiscoMT,
title = "Analysing Coreference in Transformer Outputs",
author = "Lapshinova-Koltunski, Ekaterina and Espa{\~n}a-Bonet, Cristina and van Genabith, Josef",
booktitle = "Proceedings of the Fourth Workshop on Discourse in Machine Translation (DiscoMT 2019)",
month = nov,
year = "2019",
address = "Hong Kong",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-6501",
doi = "10.18653/v1/D19-6501",
pages = "1--12"
}
Context-Aware Neural Machine Translation Decoding
Eva Martínez Garcia, Carles Creus and Cristina España-Bonet
Proceedings of the Fourth Workshop on Discourse in Machine Translation (DiscoMT 2019), pages 13-23, Hong Kong, November 2019.
[
Abstract
PDF
BibTeX
]
This work presents a decoding architecture that fuses the information from a neural translation model and the context semantics enclosed in a semantic space language model based on word embeddings. The method extends the beam search decoding process and therefore can be applied to any neural machine translation framework. With this, we sidestep two drawbacks of current document-level systems: (i) we do not modify the training process so there is no increment in training time, and (ii) we do not require document-level an-notated data. We analyze the impact of the fusion system approach and its parameters on the final translation quality for English-Spanish. We obtain consistent and statistically significant improvements in terms of BLEU and METEOR and we observe how the fused systems are able to handle synonyms to propose more adequate translations as well as help the system to disambiguate among several translation candidates for a word.
@InProceedings{martinezEtAl:DiscoMT:2019,
title = "Context-Aware Neural Machine Translation Decoding",
author = "Mart{\'\i}nez Garcia, Eva and Creus, Carles and Espa{\~n}a-Bonet, Cristina",
booktitle = "Proceedings of the Fourth Workshop on Discourse in Machine Translation (DiscoMT 2019)",
month = nov,
year = "2019",
address = "Hong Kong, China",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D19-6502",
doi = "10.18653/v1/D19-6502",
pages = "13--23"
}
Self-Supervised Neural Machine Translation
Dana Ruiter, Cristina España-Bonet and Josef van Genabith
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Volume 2: Short Papers, pages 1828-1834, Florence, Italy, August 2019.
[
Abstract
PDF
BibTeX
]
We present a simple new method where an emergent NMT system is used for simultaneously selecting training data and learning internal NMT representations. This is done in a self-supervised way without parallel data, in such a way that both tasks enhance each other during training. The method is language independent, introduces no additional hyper-parameters, and achieves BLEU scores of 29.21 (en2fr) and 27.36 (fr2en) on newstest2014 using English and French Wikipedia data for training.
@InProceedings{ruiterEtAl:ACL:2019,
author = {Dana Ruiter and Cristina Espa\~na-Bonet and Josef van Genabith},
title = "{Self-Supervised Neural Machine Translation}",
booktitle = {Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Volume 2: Short Papers. },
key = {ACL 2019},
pages = {1828--1834},
year = {2019},
month = {August},
address = {Florence, Italy},
publisher = {Association for Computational Linguistics}
}
UdS-DFKI Participation at WMT 2019: Low-Resource (en-gu) and Coreference-Aware (en-de) Systems
Cristina España-Bonet, Dana Ruiter and Josef van Genabith
Proceedings of the Fourth Conference on Machine Translation, pages 382-389, Florence, Italy, August 2019.
[
Abstract
PDF
BibTeX
]
This paper describes the UdS-DFKI submission to the WMT2019 news translation task for Gujarati-English (low-resourced pair) and German-English (document-level evaluation). Our systems rely on the on-line extraction of parallel sentences from comparable corpora for the first scenario and on the inclusion of coreference-related information in the training data in the second one.
@InProceedings{espanaEtAl:WMT:2019,
author = {Cristina Espa\~na-Bonet and Dana Ruiter and Josef van Genabith},
title = "{UdS-DFKI Participation at WMT 2019: Low-Resource ($en$--$gu$) and Coreference-Aware ($en$--$de$) Systems}",
booktitle = {Proceedings of the Fourth Conference on Machine Translation},
key = {WMT 2019},
pages = {382--389},
year = {2019},
month = {August},
address = {Florence, Italy},
publisher = {Association for Computational Linguistics}
}
2018
Neural Machine Translation is like a Pig
Cristina España-Bonet
Invited talk at the Deep Learning BCN Symposium, Barcelona, Catalunya, 20th December 2018.
[
Abstract
Slides
]
Neural machine translation systems (NMT) are state-of-the-art for most language pairs, specially for those with a large amount of parallel data available. These systems are expensive to train both in time and resources, but as with pigs, all of its parts can be (re)used afterwards. In this talk I will sketch how and why multilingual word and sentence embeddings obtained from an NMT system can be used for other purposes such as assessing semantic cross-lingual similarities, parallel sentence extraction or cross-lingual information retrieval. Under this perspective, NMT can be seen as an auxiliary task --multilingual by definition-- to obtain multilingual representations in the same way the skip-gram and CBOW tasks were defined to obtain monolingual word embeddings. Following with this analogy, I will compare differences between seq2seq and transformer architectures as two variants for the same goal.
Query Translation for Cross-lingual Search in the Academic Search Engine PubPsych (BEST PAPER AWARD)
Cristina España-Bonet, Juliane Stiller, Roland Ramthun, Josef van Genabith and Vivien Petras
Proceedings of the Metadata and Semantics Research, 12th International Research Conference (MTSR 2018), Limassol, Cyprus, October 2018.
CCIS Vol. 846 Communications in Computer and Information Science (CCIS) book series, Springer
[
Abstract
PDF
BibTeX
]
We describe a lexical resource-based process for query translation of a domain-specific and multilingual academic search engine in psychology, PubPsych. PubPsych queries are diverse in language with a high amount of informational queries and technical terminology. We present an approach for translating queries into English, German, French, and Spanish. We build a quadrilingual lexicon with aligned terms in the four languages using MeSH, Wikipedia and Apertium as our main resources. Our results show that using the quadlexicon together with some simple translation rules, we can automatically translate 85% of translatable tokens in PubPsych queries with mean adequacy over all the translatable text of 1.4 when measured on a 3-point scale [0,1,2].
@InProceedings{espanaBonetEtAl:MTSR:2018,
author = {Cristina Espa{\~n}a-Bonet and Juliane Stiller and Roland Ramthun and Josef van Genabith and Vivien Petras},
title = "{Query Translation for Cross-lingual Search in the Academic Search Engine PubPsych}",
editor="Garoufallou, Emmanouel and Sartori, Fabio and Siatri, Rania and Zervas, Marios",
booktitle="Metadata and Semantic Research",
year="2019",
publisher="Springer International Publishing",
address="Cham",
pages="37--49",
isbn="978-3-030-14401-2"
doi="10.1007/978-3-030-14401-2_4"
}
Neural Machine Translation with Context & Document Information
Cristina España-Bonet
Invited talk at the First International Workshop on Discourse Processing Guangdong University of Foreign Studies, Guangzhou, China, 23th October 2018.
The role of Artifical Intelligence within Natural Language
Cristina España-Bonet
Talk at the Multilingual Public Services in Europe Workshop, EC, Brussels, Belgium, 17th October 2018.
Multilingual Semantic Networks for Data-driven Interlingua Seq2Seq Systems
Cristina España-Bonet and Josef van Genabith
Proceedings of the LREC 2018 MLP-MomenT Workshop (MLP-Moment 2018), pages 8-13, Miyazaki, Japan, May 2018.
[
Abstract
PDF
Slides
BibTeX
]
Neural machine translation systems are state-of-the-art for most language pairs despite the fact that they are relatively recent and that because of this there is likely room for even further improvements. Here, we explore whether, and if so, to what extent, semantic networks can help improve NMT. In particular, we (i) study the contribution of the nodes of the semantic network, synsets, as factors in multilingual neural translation engines. We show that they improve a state-of-the-art baseline and that they facilitate the translation from languages that have not been seen at all in training (beyond zero-shot translation). Taking this idea to an extreme, we (ii) use synsets as the basic unit to encode the input and turn the source language into a data-driven interlingual language. This transformation boosts the performance of the neural system for unseen languages achieving an improvement of 4.9/6.3 and 8.2/8.7 points of BLEU/METEOR for fr2en and es2en respectively when neither corpora in fr or es has been used. In (i), the enhancement comes about because cross-language synsets help to cluster words by semantics irrespective of their language and to map the unknown words of a new language into the multilingual clusters. In (ii), because with the data-driven interlingua there is no unknown language if it is covered by the semantic network. However, non-content words are not represented in the semantic network, and a higher level of abstraction is still needed in order to go a step further and train these systems with only monolingual corpora for example.
@InProceedings{espanaVanGenabith:LREC:2018,
author = {Cristina Espa\~na-Bonet and Josef van Genabith},
title = "{Multilingual Semantic Networks for Data-driven Interlingua Seq2Seq Systems}",
booktitle = {Proceedings of the LREC 2018 MLP-MomenT Workshop},
key = {MLP-MomenT 2018},
pages = {8--13},
year = {2018},
month = {May},
Address = {Miyazaki, Japan}
}
2017
Going beyond zero-shot MT: combining phonological, morphological and semantic factors. The UdS-DFKI System at IWSLT 2017
Cristina España-Bonet and Josef van Genabith
Proceedings of the 14th International Workshop on Spoken Language Translation (IWSLT), pages 15-22, Tokyo, Japan, December 2017.
[
Abstract
PDF
Poster
BibTeX
]
This paper describes the UdS-DFKI participation to the multilingual task of the IWSLT Evaluation 2017. Our approach is based on factored multilingual neural translation systems following the small data and zero-shot training conditions. Our systems are designed to fully exploit multilinguality by including factors that increase the number of common elements among languages such as phonetic coarse encodings and synsets, besides shallow part-of-speech tags, stems and lemmas. Document level information is also considered by including the topic of every document. This approach improves a baseline without any additional factor for all the language pairs and even allows beyond-zero-shot translation. That is, the translation from unseen languages is possible thanks to the common elements —especially synsets in our models— among languages.
@InProceedings{espanaVanGenabith:IWSLT:2017,
author = {Cristina Espa\~na-Bonet and Josef van Genabith},
title = "{Going beyond zero-shot MT: combining phonological, morphological and semantic factors. The UdS-DFKI System at IWSLT 2017}",
booktitle = {Proceedings of the 14th International Workshop on Spoken Language Translation (IWSLT)},
key = {IWSLT 2017},
pages = {15--22},
year = {2017},
month = {December},
Address = {Tokyo, Japan}
}
Multilingual Natural Language Processing
Cristina España-Bonet
Talk at RICOH Institute of ICT, Tokyo, Japan, 11th December 2017.
An Empirical Analysis of NMT-Derived Interlingual Embeddings and their Use in Parallel Sentence Identification
Cristina España-Bonet, Ádám Csaba Varga, Alberto Barrón-Cedeño and Josef van Genabith
IEEE Journal of Selected Topics in Signal Processing, volume 11, number 8, pages 1340-1350, IEEE, December 2017.
[
Abstract
PDF
BibTeX
HTML
]
End-to-end neural machine translation has overtaken statistical machine translation in terms of translation quality for some language pairs, specially those with a large amount of parallel data available. Beside this palpable improvement, neural networks embrace several new properties. A single system can be trained to translate between many languages at almost no additional cost other than training time. Furthermore, internal representations learned by the network serve as a new semantic representation of words -or sentences- which, unlike standard word embeddings, are learned in an essentially bilingual or even multilingual context. In view of these properties, the contribution of the present work is two-fold. First, we systematically study the context vectors, i.e. output of the encoder, and their prowess as an interlingua representation of a sentence. Their quality and effectiveness are assessed by similarity measures across translations, semantically related, and semantically unrelated sentence pairs. Second, and as extrinsic evaluation of the first point, we identify parallel sentences in comparable corpora, obtaining an F1=98.2% on data from a shared task when using only context vectors. F1 reaches 98.9% when complementary similarity measures are used.
@article{espana-bonetElAl:2017,
author = {Cristina Espa{\~{n}}a{-}Bonet and
{\'{A}}d{\'{a}}m Csaba Varga and
Alberto Barr{\'{o}}n{-}Cede{\~{n}}o and
Josef van Genabith},
title = {An Empirical Analysis of NMT-Derived Interlingual Embeddings and their
Use in Parallel Sentence Identification},
journal = {IEEE Journal of Selected Topics in Signal Processing},
volume = {11},
number = {8},
month = {December},
pages = {1340--1350},
year = {2017},
doi = {10.1109/JSTSP.2017.2764273}
}
Learning Bilingual Projections of Embeddings for Vocabulary Expansion in Machine Translation
Pranava Swaroop Madhyastha and Cristina España-Bonet
Proceedings of the 2nd Workshop on Representation Learning for NLP (ACL Workshop RepL4NLP-2017), pages 139-145, Vancouver, Canada, August 2017.
[
Abstract
PDF
Poster
BibTeX
]
We propose a simple log-bilinear softmax-based model to deal with vocabulary expansion in machine translation. Our model uses word embeddings trained on significantly large unlabelled monolingual corpora and learns over a fairly small, word-to-word bilingual dictionary. Given an out-of-vocabulary source word, the model generates a probabilistic list of possible translations in the target language using the trained bilingual embeddings. We integrate these translation options into a standard phrase-based statistical machine translation system and obtain consistent improvements in translation quality on the EnglishâSpanish language pair. When tested over an out-of-domain test set, we get a significant improvement of 3.9 BLEU points.
@inProceedings{MadhyasthaEspana:2017,
author = {Pranava Swaroop Madhyastha and Cristina Espa{\~{n}}a{-}Bonet},
title = {Learning Bilingual Projections of Embeddings for Vocabulary Expansion in Machine Translation},
booktitle = {Proceedings of the 2nd Workshop on Representation Learning for NLP. ACL Workshop on Representation Learning for NLP (RepL4NLP-2017)},
pages = {139--145},
year = {2017},
month = {August}
address = {Vancouver, Canada},
publisher = {Association for Computational Linguistics},
language = {english},
}
Lump at SemEval-2017 Task 1: Towards an Interlingua Semantic Similarity
Cristina España-Bonet and Alberto Barrón-Cedeño
Proceedings of the 11th International Workshop on Semantic Evaluation (ACL Workshop SemEval-2017), pages 144-149, Vancouver, Canada, August 2017.
[
Abstract
PDF
BibTeX
arXiv
]
This is the Lump team participation at SemEval 2017 Task 1 on Semantic Textual Similarity. Our supervised model relies on features which are multilingual or interlingual in nature. We include lexical similarities, cross-language explicit semantic analysis, internal representations of multilingual neural networks and interlingual word embeddings. Our representations allow to use large datasets in language pairs with many instances to better classify instances in smaller language pairs avoiding the necessity of translating into a single language. Hence we can deal with all the languages in the task: Arabic, English, Spanish, and Turkish.
@InProceedings{EspanaBarron:2017,
author = {{Espa{\~n}a-Bonet}, Cristina and {Barr\'on-Cede{\~n}o}, Alberto},
title = "{Lump at SemEval-2017 Task 1: Towards an Interlingua Semantic Similarity}",
booktitle = "{Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017)}",
pages = {144--149},
year = {2017},
month = {August}
address = {Vancouver, Canada},
publisher = {Association for Computational Linguistics},
language = {english},
url = {http://www.aclweb.org/anthology/S17-2019}
}
Using Word Embeddings to Enforce Document-Level Lexical Consistency in Machine Translation
Eva Martínez Garcia, Carles Creus, Cristina España-Bonet, Lluís Màrquez
The 20th Annual Conference of the European Association for Machine Translation, Prague, Czech Republic. The Prague Bulletin of Mathematical Linguistics, Vol. 108, pages 85-96, June 2017.
[
Abstract
PDF
BibTeX
arXiv
]
We integrate new mechanisms in a document-level machine translation decoder to improve the lexical consistency of document translations. First, we develop a document-level feature designed to score the lexical consistency of a translation. This feature, which applies to words that have been translated into different forms within the document, uses word embeddings to measure the adequacy of each word translation given its context. Second, we extend the decoder with a new stochastic mechanism that, at translation time, allows to introduce changes in the translation oriented to improve its lexical consistency. We evaluate our system on English-Spanish document translation, and we conduct automatic and manual assessments of its quality. The automatic evaluation metrics, applied mainly at sentence level, do not reflect significant variations. On the contrary, the manual evaluation shows that the system dealing with lexical consistency is preferred over both a standard sentence-level and a standard document-level phrase-based MT systems.
@Article{eamt_martinezetal:2017,
author = {{Mart\'inez}, Eva and {Creus}, Carles and {Espa{\~n}a-Bonet}, Cristina and {M\`arquez}, Llu\'{i}s},
title = {Using Word Embeddings to Enforce Document-Level Lexical Consistency in Machine Translation},
journal = {The 20th Annual Conference of the European Association for Machine Translation.
The Prague Bulletin of Mathematical Linguistics},
pages = {85--96},
volume = {108},
year = {2017},
month = {June},
language = {english}
}
2016
Automatic Speech Recognition with Deep Neural Networks for Impaired Speech
Cristina España-Bonet and José A. R. Fonollosa
Chapter in Advances in Speech and Language Technologies for Iberian Languages, part of the series Lecture Notes in Artificial Intelligence. In A. Abad et al. (Eds.). IberSPEECH 2016, LNAI 10077, Chapter 10, pages 97-107, October 2016.
[
Abstract
PDF
BibTeX
arXiv
]
Automatic Speech Recognition has reached almost human performance in some controlled scenarios. However, recognition of impaired speech is a difficult task for two main reasons: data is (i) scarce and (ii) heterogeneous. In this work we train different architectures on a database of dysarthric speech. A comparison between architectures shows that, even with a small database, hybrid DNN-HMM models outperform classical GMM-HMM according to word error rate measures. A DNN is able to improve the recognition word error rate a 13% for subjects with dysarthria with respect to the best classical architecture. This improvement is higher than the one given by other deep neural networks such as CNNs, TDNNs and LSTMs. All the experiments have been done with the Kaldi toolkit for speech recognition for which we have adapted several recipes to deal with dysarthric speech and work on the TORGO database. These recipes are publicly available.
@inBook{EspanaFonollosa:2016,
author = {Espa\~{n}a-Bonet, Cristina and Fonollosa, Jos\'{e} A. R.},
title = {Automatic Speech Recognition with Deep Neural Networks for Impaired Speech},
booktitle = {Advances in Speech and Language Technologies for Iberian Languages},
series = {Lecture Notes in Artificial Intelligence},
month = {October},
year = {2016},
publisher = {Springer International Publishing AG},
editor = {Abad, A. and Ortega, A. and Teixeira, A.J.d.S. and Garcia Mateo, C. and Mart\'{i}nez Hinarejos, C.D.
and Perdig\~{a}o, F. and Batista, F. and Mamede, N. (Eds.)},
pages = {97--107},
chapter = 10,
isbn = {978-3-319-49169-1},
doi = {10.1007/978-3-319-49169-1$\_$10},
url = {http://www.springer.com/us/book/9783319491684}
}
The TALP-UPC Spanish-English WMT Biomedical Task: Bilingual Embeddings and Char-based Neural Language Model Rescoring in a Phrase-based System
Marta Ruiz Costa-jussà, Cristina España-Bonet, Pranava Madhyastha, Carlos Escolano and José A. R. Fonollosa
Proceedings of the First Conference on Machine Translation (WMT 2016), pages 463-468, Berlin, Germany, August 2016.
[
Abstract
PDF
BibTeX
arXiv
]
This paper describes the TALP-UPC system in the Spanish-English WMT 2016 biomedical shared task. Our system is a standard phrase-based system enhanced with vocabulary expansion using bilingual word embeddings and a character-based neural language model with rescoring. The former focuses on resolving out-of-vocabulary words, while the latter enhances the fluency of the system. The two modules progressively improve the final translation as measured by a combination of several lexical metrics.
@InProceedings{costajussaEtal:WMT:2016,
author = {Costa-juss\`{a}, Marta R. and Espa\~{n}a-Bonet, Cristina and Madhyastha, Pranava and
Escolano, Carlos and Fonollosa, Jos\'{e} A. R.},
title = {The TALP--UPC Spanish--English WMT Biomedical Task: Bilingual Embeddings and
Char-based Neural Language Model Rescoring in a Phrase-based System},
booktitle = {Proceedings of the First Conference on Machine Translation},
month = {August},
year = {2016},
address = {Berlin, Germany},
publisher = {Association for Computational Linguistics},
pages = {463--468},
url = {http://www.aclweb.org/anthology/W/W16/W16-2336}
}
Resolving Out-of-Vocabulary Words with Bilingual Embeddings in Machine Translation
Pranava Madhyastha and Cristina España-Bonet
CoRR abs/1608.01910, August 2016.
[
Abstract
PDF
BibTeX
arXiv
]
Out-of-vocabulary words account for a large proportion of errors in machine translation systems, especially when the system is used on a different domain than the one where it was trained. In order to alleviate the problem, we propose to use a log-bilinear softmax-based model for vocabulary expansion, such that given an out-of-vocabulary source word, the model generates a probabilistic list of possible translations in the target language. Our model uses only word embeddings trained on significantly large unlabelled monolingual corpora and trains over a fairly small, word-to-word bilingual dictionary. We input this probabilistic list into a standard phrase-based statistical machine translation system and obtain consistent improvements in translation quality on the English-Spanish language pair. Especially, we get an improvement of 3.9 BLEU points when tested over an out-of-domain test set.
@article{MadhyasthaEspana:2016,
author = {Pranava Swaroop Madhyastha and Cristina Espa{\~{n}}a{-}Bonet},
title = {Resolving Out-of-Vocabulary Words with Bilingual Embeddings in Machine Translation},
journal = {CoRR},
volume = {abs/1608.01910},
year = {2016},
url = {http://arxiv.org/abs/1608.01910}
}
Hybrid Machine Translation Overview
Cristina España-Bonet, Marta Ruiz Costa-jussà
Chapter in Hybrid Approaches to Machine Translation, part of the series Theory and Applications of Natural Language Processing, pages 1-24
[
Abstract
PDF
BibTeX
]
This survey chapter provides an overview of the recent research in hybrid Machine Translation (MT). The main MT paradigms are sketched and their integration at different levels of depth is described starting with system combination techniques and followed by integration strategies led by rule-based and statistical systems. System combination does not involve any hybrid architecture since it combines translation outputs. It can be done with different granularities that include sentence, sub-sentential and graph-levels. When considering a deeper integration, architectures guided by the rule-based approach introduce statistics to enrich resources, modules or the backbone of the system. Architectures guided by the statistical approach include rules in pre-/post-processing or at a inner level which means including rules or dictionaries in the core system. This chapter overviewing hybrid MT puts in context, introduces, and motivates the subsequent chapters that constitute this book.
@Inbook{EspanaBonetEtal:2016,
author={Espa{\~{n}}a-Bonet, Cristina and Costa-juss{\`a}, Marta R.},
editor={Costa-juss{\`a}, R. Marta and Rapp, Reinhard and Lambert, Patrik
and Eberle, Kurt and Banchs, E. Rafael and Babych, Bogdan},
title="{Hybrid Machine Translation Overview}",
bookTitle="{Hybrid Approaches to Machine Translation"},
year={2016},
publisher={Springer International Publishing},
pages={1--24},
isbn={978-3-319-21311-8},
doi={10.1007/978-3-319-21311-8_1},
url={http://dx.doi.org/10.1007/978-3-319-21311-8_1}}
TweetMT: A Parallel Microblog Corpus
Iñaki San Vicente, Iñaki Alegria, Cristina España-Bonet, Pablo Gamallo, Hugo Gonçalo Oliveira, Eva Martínez Garcia, Antonio Toral, Arkaitz Zubiaga and Nora Aranberri
Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), pages 2936-2941, Portoroz, Slovenia, May 2016.
[
Abstract
PDF
BibTeX
arXiv
]
We introduce TweetMT, a parallel corpus of tweets in four language pairs that combine five languages (Spanish from/to Basque, Catalan, Galician and Portuguese), all of which have an official status in the Iberian Peninsula. The corpus has been created by combining automatic collection and crowdsourcing approaches, and it is publicly available. It is intended for the development and testing of microtext machine translation systems. In this paper we describe the methodology followed to build the corpus, and present the results of the shared task in which it was tested.
@InProceedings{LRECSanVicente:2016,
author = {{San Vicente}, I\~naki and {Alegr\'ia}, I{\~n}aki and {Espa{\~n}a-Bonet}, Cristina and {Gamallo}, Pablo and
{Gon\c{c}alo Oliveira}, Hugo and {Mart\'inez Garc\'ia}, Eva and
{Toral}, Antonio and {Zubiaga}, Arkaitz and {Aranberri}},
title = {TweetMT: A Parallel Microblog Corpus},
booktitle = {Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016)},
pages = {2936--2941},
year = {2016},
month = {may},
date = {23--28},
location = {Portoroz, Slovenia},
editor = {Nicoletta Calzolari (Conference Chair) and Khalid Choukri and Thierry Declerck and Marko Grobelnik and Bente Maegaard and Joseph Mariani and Asuncion Moreno and Jan Odijk and Stelios Piperidis},
publisher = {European Language Resources Association (ELRA)},
isbn = {978-2-9517408-9-1},
language = {english}
}
}
Resolving Out-of-Vocabulary Words with Bilingual Word Embeddings in Machine Translation
Cristina España-Bonet
Invited talk at Saarland University, DFKI, Saarbrücken, April 29th, 2016.
[
Abstract
Slides
]
Data-driven machine translation systems are able to translate words that have been seen in the training parallel corpora. However, translating out-of-vocabulary words (OOV) is still a major challenge, even for the best performing systems. In this talk, I will show a method that takes advantage of distributional semantic representations of words —previously estimated on large monolingual corpora—, to obtain a probabilistic distribution of translation options for a given OOV. The monolingual embeddings are projected into a bilingual low-dimensional space by learning a log-linear model over a small parallel dictionary. Within the translation setting, the probabilistic distribution interacts with other components (e.g., a language model), which allows for selecting the best translation option among all the possibilities, even if a word has not been seen in the parallel corpus. Our model achieves significant improvements in terms of translation quality, especially for out-of-domain data, in which out-of-vocabulary content words are expected. I will show here how and when our method boosts the performance of a translation system, and present our recent participation with this approach in the Biomedical Translation Task in WMT16.
2015
WikiParable - Data Categorisation Platform (Version 1.0)
Cristina España-Bonet
Technical Report, Universitat Politècnica de Catalunya, Computer Science Department, November 2015.
[
Abstract
PDF
BibTeX
arXiv
]
This document describes WikiParable, an on-line platform designed for data categorisation. Its purpose is twofold and the tool can be used both to annotate data and to evaluate automatic categorisations. As a main use case and aim of the implementation, the interface has been used within the TACARDI project to annotate Wikipedia articles in different domains and languages.
@TechReport{WikiParableV1.0,
author = {{Espa{\~n}a-Bonet}, Cristina}
title = {WikiParable -- Data Categorisation Platform (Version 1.0) },
year = {2015},
month = {November}
date = {16},
institution = {Universitat Polit\`ecnica de Catalunya, Computer Science Department},
url = {http://hdl.handle.net/2117/79539},
language = {english}
}
Journey through Natural Language Processing
Cristina España-Bonet
Poster at Google NLP PhD Summit 2015, Zurich, Switzerland, September 2015.
[
Abstract
PDF
BibTeX
arXiv
]
Summary of some of the work I have been involved in in the last three years.
@Misc{CEBjourney,
author = {{Espa{\~n}a-Bonet}, Cristina}
title = {Journey through Natural Language Processing},
howpublished = {Poster},
year = {2015},
month = {September}
date = {23},
address = {Zurich, Switzerland},
language = {english}
}
Overview of TweetMT: A Shared Task on Machine Translation of Tweets at SEPLN 2015
Iñaki Alegria, Nora Aranberri, Cristina España-Bonet, Pablo Gamallo, Hugo Gonçalo Oliveira, Eva Martínez Garcia, Iñaki San Vicente, Antonio Toral, Arkaitz Zubiaga
Proceedings of the Tweet Translation Workshop, at "XXXI Congreso de la Sociedad Española de Procesamiento de lenguaje natural" and CEUR Workshop Proceedings, volume 1445, pages 8-19, Alacant, Spain, September 2015.
[
Abstract
PDF
BibTeX
arXiv
Slides
]
This article presents an overview of the shared task that took place as part of the TweetMT workshop held at SEPLN 2015. The task consisted in translating collections of tweets from and to several languages. The article outlines the data collection and annotation process, the development and evaluation of the shared task, as well as the results achieved by the participants.
@InProceedings{tweetMT_overview,
author = {{Alegr\'ia}, I{\~n}aki and {Aranberri}, Nora and {Espa{\~n}a-Bonet}, Cristina and {Gamallo}, Pablo and
{Gon\c{c}alo Oliveira}, Hugo and {Mart\'inez Garc\'ia}, Eva and {San Vicente}, I\~naki and
{Toral}, Antonio and {Zubiaga}, Arkaitz},
title = {Overview of TweetMT: A Shared Task on Machine Translation of Tweets at SEPLN 2015},
booktitle = {Proceedings of the Tweet Translation Workshop, at "XXXI Congreso de la Sociedad Espa{\~n}ola de
Procesamiento de lenguaje natural" and CEUR Workshop Proceedings.},
pages = {8--19},
volume = {1445},
year = {2015},
month = {September}
date = {15},
address = {Alacant, Spain},
language = {english}
}
The UPC TweetMT participation: Translating Formal Tweets using Context Information
Eva Martínez Garcia, Cristina España-Bonet, Lluís Màrquez
Proceedings of the Tweet Translation Workshop, at "XXXI Congreso de la Sociedad Española de Procesamiento de lenguaje natural" and CEUR Workshop Proceedings, volume 1445, pages 25-32, Alacant, Spain, September 2015.
[
Abstract
PDF
BibTeX
arXiv
]
In this paper, we describe the UPC systems participating in the TweetMT shared task. We developed two main systems that were applied to the Spanish–Catalan language pair: a state-of-the-art phrase-based statistical machine translation system and a context-aware system. In the second approach, we define "context" for a tweet as the tweets of a user produced in the same day, and also, we study the impact of this kind of information in the final translations when using a document-level decoder. A variant of this approach considers also semantic information from bilingual embeddings.
@InProceedings{tweetMT_martinezetal15,
author = {{Mart\'inez}, Eva and {Espa{\~n}a-Bonet}, Cristina and {M\`arquez}, Llu\'{i}s},
title = {The UPC TweetMT participation: Translating Formal Tweets using Context Information},
booktitle = {Proceedings of the Tweet Translation Workshop, at "XXXI Congreso de la Sociedad Espa{\~n}ola de
Procesamiento de lenguaje natural" and CEUR Workshop Proceedings.},
pages = {25--32},
volume = {1445},
year = {2015},
month = {September}
date = {15},
address = {Alacant, Spain},
language = {english}
}
A Factory of Comparable Corpora from Wikipedia
Alberto Barrón-Cedeño, Cristina España-Bonet, Josu Boldoba, Lluís Màrquez
Proceedings of the 8th Workshop on Building and Using Comparable Corpora (BUCC), pages 3-13, Beijing, China, July 2015.
[
Abstract
PDF
BibTeX
arXiv
]
Multiple approaches to grab comparable data from the Web have been developed up to date. Nevertheless, coming out with a high-quality comparable corpus of a specific topic is not straightforward. We present a model for the automatic extraction of comparable texts in multiple languages and on specific topics from Wikipedia. In order to prove the value of the model, we automatically extract parallel sentences from the comparable collections and use them to train statistical machine translation engines for specific domains. Our experiments on the English-Spanish pair in the domains of Computer Science, Science, and Sports show that our in-domain translator performs significantly better than a generic one when translating in-domain Wikipedia articles. Moreover, we show that these corpora can help when translating out-of-domain texts.
@InProceedings{Barronetal:2015,
author = {{Barr\'on-Cede{\~n}o}, Alberto and {Espa{\~n}a-Bonet}, Cristina and
{Boldoba}, Josu and {M\`arquez}, Llu\'{i}s},
title = "{A Factory of Comparable Corpora from Wikipedia}",
booktitle = "{Proceedings of the 8th Workshop on Building and Using Comparable Corpora (BUCC)}",
pages = {3--13},
year = {2015},
month = {July}
date = {30},
address = {Beijing, China},
language = {english},
url = {http://www.aclweb.org/anthology/W15-3402}
}
Document-Level Machine Translation with Word Vector Models
Eva Martínez Garcia, Cristina España-Bonet, Lluís Màrquez
Proceedings of the 18th Annual Conference of the European Association for Machine Translation (EAMT), pages 59-66, Antalya, Turkey, May 2015.
[
Abstract
PDF
BibTeX
arXiv
]
In this paper we apply distributional semantic information to
document-level machine translation. We train monolingual and bilingual word vector models on large corpora and we
evaluate them first in a cross-lingual lexical substitution task and then on the final translation task.
For translation, we incorporate the semantic information in a statistical document-level decoder (Docent), by enforcing
translation choices that are semantically similar to the context. As expected, the bilingual word vector models are more
appropriate for the purpose of translation. The final document-level translator incorporating the semantic model
outperforms the basic Docent (without semantics) and also performs slightly over a standard sentence-level SMT system
in terms of ULC (the average of a set of standard automatic evaluation metrics for MT). Finally, we also present some
manual analysis of the translations of some concrete documents.
@InProceedings{eamt15_martinezetal15,
author = {{Mart\'inez}, E. and {Espa{\~n}a-Bonet}, C. and {M\`arquez}, L.},
title = {Document-Level Machine Translation with Word Vector Models},
booktitle = {Proceedings of the 18th Annual Conference of the European Association for Machine Translation (EAMT)},
pages = {59--66},
year = {2015},
month = {May}
date = {13},
address = {Antalya, Turkey},
language = {english}
}
A broad stroke on Machine Translation Evaluation
Cristina España-Bonet
Invited talk at the Faculty of Informatics (UPV/EHU) Donosti, March 13, 2015.
[
Abstract
Slides
]
This broad stroke on Machine Translation Evaluation overviews current approaches and methodologies.
MT evaluation is put in context and we argue why it must be considered a delicate topic. The most
common manual and automatic evaluation measures are described and new approaches sketched. Finally,
several tools for MT evaluation are introduced paying special attention to the Asiya Toolkit.
2014
Word's Vector Representations meet Machine Translation
Eva Martínez Garcia, Cristina España-Bonet, Jörg Tiedemann, Lluís Màrquez
Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, pages 132-134, October 25, 2014, Doha, Qatar.
[
Abstract
PDF
BibTeX
arXiv
]
Distributed vector representations of words are useful in various NLP tasks.
We briefly review the CBOW approach and propose a bilingual application of
this architecture with the aim to improve consistency and coherence of Machine
Translation. The primary goal of the bilingual extension is to handle ambiguous
words for which the different senses are conflated in the monolingual setup.
@InProceedings{sst8_martinezetal14,
author = {{Mart\'inez}, E. and {Espa{\~n}a-Bonet}, C. and {Tiedemann}, J. and {M\`arquez}, L.},
title = {Word's Vector Representations meet Machine Translation},
booktitle = {Proceedings of the eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8)},
pages = {132--134},
year = {2014},
month = {October}
date = {25},
address = {Doha, Qatar},
language = {english}
}
A hybrid machine translation architecture guided by syntax
Gorka Labaka, Cristina España-Bonet, Lluís Màrquez, Kepa Sarasola
Machine Translation Journal, Vol. 28, Issue 2, pages 91-125, October, 2014.
[
Abstract
PDF
BibTeX
arXiv
]
This article presents a hybrid architecture which combines rule-based machine translation (RBMT) with phrase-based statistical machine translation (SMT). The hybrid translation system is guided by the rule-based engine. Before the transfer step, a varied set of partial candidate translations is calculated with the SMT system and used to enrich the tree-based representation with more translation alternatives. The final translation is constructed by choosing the most probable combination among the available fragments using monotone statistical decoding following the order provided by the rule-based system. We apply the hybrid model to a pair of distantly related languages, Spanish and Basque, and perform extensive experimentation on two different corpora. According to our empirical evaluation, the hybrid approach outperforms the best individual system across a varied set of automatic translation evaluation metrics. Following some output analysis to better understand the behaviour of the hybrid system, we explore the possibility of adding alternative parse trees and extra features to the hybrid decoder. Finally, we present a twofold manual evaluation of the translation systems studied in this paper, consisting of (i) a pairwise output comparison and (ii) a individual task-oriented evaluation using HTER. Interestingly, the manual evaluation shows some contradictory results with respect to the automatic evaluation; humans tend to prefer the translations from the RBMT system over the statistical and hybrid translations.
@article{labakaetal14,
author = {Labaka, Gorka and Espa{\~n}a-Bonet, Cristina and M\`arquez, Llu\'is and Sarasola, Kepa},
title = {A hybrid machine translation architecture guided by syntax},
journal = {Machine Translation},
doi = {10.1007/s10590-014-9153-0},
volume = 28,
issue = 2,
pages = {91-125},
year = {2014},
month = {October},
issn = {0922-6567},
url = {http://dx.doi.org/10.1007/s10590-014-9153-0},
publisher = {Springer Netherlands}
}
Document-Level Machine Translation as a Re-translation Process
Eva Martínez Garcia, Cristina España-Bonet, Lluís Màrquez
Procesamiento del Lenguaje Natural, 53, 103-110. September, 2014
[
Abstract
PDF
BibTeX
arXiv
]
Most of the current Machine Translation systems are designed to translate a document sentence by sentence ignoring discourse information and producing incoherencies in the final translations. In this paper we present some document-level-oriented post-processes to improve translations' coherence and consistency. Incoherences are detected and new partial translations are proposed. The work focuses on studying two phenomena: words with inconsistent translations throughout a text and also, gender and number agreement among words. Since we deal with specific phenomena, an automatic evaluation does not reflect significant variations in the translations. However, improvements are observed through a manual evaluation.
@article{martinez14,
author = {{Mart\'inez}, E. and {Espa{\~n}a-Bonet}, C. and {M\`arquez}, L.},
title = {Document-Level Machine Translation as a Re-translation Process},
journal = {Procesamiento del Lenguaje Natural},
volume = 53,
pages = {103--110},
year = {2014},
month = {September}
}
Statistical Machine Translation and Automatic Evaluation
Cristina España-Bonet and Meritxell Gonzàlez
Tutorial at the 9th edition of the Language Resources and Evaluation Conference, Reykjavik, May 2014.
[
Abstract
Slides Part I
Slides Part II
BibTeX
]
The tutorial is divided in two main parts. The main objective of the first part is to get to know the fundamentals behind the three modules of a statistical system: the language model, the translation model and the decoding or search for the best translation.
The presentation, although theoretical, is focused on understanding how standard software such as SRILM [Stolcke, 2002] and Moses [Koehn et al., 2007] work, what's the logic behind them, so that it is easy to understand the extensions and modifications available.
We also devote the second part of the tutorial to see how these systems, and machine translation systems in general, are evaluated automatically. Machine translation evaluation is a delicate topic. Here we will put the evaluation into context, describe in detail the standard metrics and overview other existing possibilities and paradigms such as linguistically motivated measures and confidence estimation.
Both parts end with a video devoted to reproduce how to build in practice a phrase-based statistical machine translation system (PartI) and how to deeply evaluate translation systems (PartII).
Webpage: http://slifer.lsi.upc.edu/lrec-mttutorial
@Unpublished{tutorialLREC14,
author = {{Espa{\~n}a-Bonet}, C. and {Gonz\`alez}, M.},
title = {Statistical Machine Translation and Automatic Evaluation},
booktitle = {Tutorial at the Ninth International Conference on Language Resources and Evaluation (LREC'14)},
url = {http://slifer.lsi.upc.edu/lrec-mttutorial}
year = {2014},
month = {may},
date = {26--31},
address = {Reykjavik, Iceland},
language = {english}}
2013
Wikicardi: Hacia la extracción de oraciones paralelas de Wikipedia
Josu Boldoba, Alberto Barrón-Cedeño, Cristina España-Bonet
Research Report LSI-14-3-R
[
Abstract
PDF
BibTeX
arXiv
]
Uno de los objetivos del proyecto Tacardi (TIN2012-38523-C02-00) consiste en extraer oraciones paralelas de corpus comparables para enriquecer y adaptar traductores automáticos. En esta investigación usamos un subconjunto de Wikipedia como corpus comparable. En este reporte se describen nuestros avances con respecto a la extracción de fragmentos paralelos de Wikipedia. Primero, discutimos cómo hemos definido los tres dominios de interés -ciencia, informática y deporte-, en el marco de la enciclopedia y cómo hemos extraído los textos y demás datos necesarios para la caracterización de los artículos en las distintas lenguas. Después discutimos brevemente los modelos que usaremos para identificar oraciones paralelas y damos sólo una muestra de algunos resultados preliminares. Los datos obtenidos hasta ahora permiten vislumbran que será posible extraer oraciones paralelas de los dominios de interés a corto plazo, si bien aún no contamos con una estimación del volumen de éstos.
@TechReport{boldobaLSI143R,
author = {{Boldoba}, J. and {Barr\'on-Cede{\~n}o}, A. and {Espa{\~n}a-Bonet}, C.},
title = {Wikicardi: Hacia la extracci\'on de oraciones paralelas de Wikipedia},
institution = {LSI, UPC},
year = {2014},
month = {January},
type = {Research Report},
number = {LSI-14-3-R}
}
Experiments on Document Level Machine Translation
Eva Martínez Garcia, Lluís Màrquez, Cristina España-Bonet
Research Report LSI-14-11-R
[
Abstract
PDF
BibTeX
arXiv
]
.
@TechReport{cespanaLSI093R,
author = {{Mart\'inez}, E. and {M\`arquez}, L. and {Espa{\~n}a-Bonet}, C.},
title = {Experiments on Document Level Machine Translation},
institution = {LSI, UPC},
year = {2014},
month = {January},
type = {Research Report},
number = {LSI-14-11-R}
}
MT Techniques in a Retrieval System of Semantically Enriched Patents
Meritxell Gonzàlez, Maria Mateva, Ramona Enache, Cristina España-Bonet, Lluís Màrquez, Borislav Popov, Aarne Ranta
Proceedings of the Machine Translation Summit XIV, Nice, France, September 2-6, 2013.
[
Abstract
PDF
BibTeX
arXiv
]
This paper focuses on how automatic translation techniques integrated in a
patent retrieval system increase its capabilities and make possible extended
features and functionalities. We describe 1) a novel methodology for natural language
to SPARQL translation based on a grammarâontology interoperability automation
and a query grammar for the patents domain; 2) a devised strategy for statistical-based
translation of patents that allows to transfer semantic annotations to the target
language; 3) a built-in knowledge representation infrastructure that uses multilingual
semantic annotations; and 4) an on'line application that offers a multilingual
search interface over structural knowledge databases (domain ontologies) and multilingual
documents (biomedical patents) that have been automatically translated.
@InProceedings{MTSpropotype,
author = {{Gonz\`alez}, M. and {Mateva}, M. and {Enache}, R. and {Espa{\~n}a-Bonet}, C. and {M\`arquez}, L. and {Ranta}, A.},
title = {MT Techniques in a Retrieval System of Semantically Enriched Patents},
booktitle = {Proceedings of the Machine Translation Summit XIV},
pages = {-},
year = {2013},
month = {sep},
date = {2},
address = {Nice, France},
language = {english}
}
2012
Deep evaluation of hybrid architectures: Use of different metrics in MERT weight optimization
Cristina España-Bonet, Gorka Labaka, Arantza Díaz de Ilarraza, Lluís Màrquez, Kepa Sarasola
Proceedings of the Free/Open-Source Rule-Based Machine Translation Workshop, Gothenburg 14-15 June, 2012.
[
Abstract
PDF
Slides
BibTeX
arXiv
]
The process of developing hybrid MT systems is usually guided by
an evaluation method used to compare different combinations of basic subsystems. This work presents a deep
evaluation experiment of a hybrid architecture, which combines rule-based and statistical
translation approaches. Differences between the results obtained from automatic and human
evaluations corroborate the inappropriateness of pure lexical automatic evaluation metrics
to compare the outputs of systems that use very different translation approaches. An examination
of sentences with controversial results suggested that linguistic well-formedness
should be considered in the evaluation of output translations. Following this idea, we have
experimented with a new simple automatic evaluation metric, which combines lexical and
PoS information. This measure showed higher agreement with human assessments than
BLEU in a previous study (Labaka et al., 2011). In this paper we have extended its usage throughout
the system development cycle, focusing on its ability to improve parameter optimization.
Results are not totally conclusive. Manual evaluation reflects a slight improvement,
compared to BLEU, when using the proposed measure in system optimization. However,
the improvement is too small to draw any clear conclusion. We believe that we should
first focus on integrating more linguistically representative features in the developing of the
hybrid system, and then go deeper into the development of automatic evaluation metrics.
@InProceedings{SMatxinTeval2,
author = {{Espa{\~n}a-Bonet}, C. and {Labaka}, G. and {D\'iaz de Ilarraza}, A. and {M\`arquez}, L.
and {Sarasola}, K.},
title = {Deep evaluation of hybrid architectures: Use of different metrics in MERT weight optimization},
booktitle = {Proceedings of the Free/Open-Source Rule-Based Machine Translation Workshop},
pages = {65-76},
year = {2012},
month = {jun},
date = {14--15},
address = {Gothenburg},
language = {english}
}
A Hybrid System for Patent Translation
Ramona Enache, Cristina España-Bonet, Aarne Ranta, Lluís Màrquez
Proceedings of the 16th Annual Conference of the European Association for Machine Translation (EAMT12), Trento, Italy, May 8-30, 2012.
[
Abstract
PDF
BibTeX
arXiv
]
This work presents a HMT system for
patent translation. The system exploits the
high coverage of SMT and the high precision of an RBMT system based on GF to
deal with specific issues of the language.
The translator is specifically developed to
translate patents and it is evaluated in the
English-French language pair. Although
the number of issues tackled by the grammar are not extremely numerous yet, both
manual and automatic evaluations consistently show their preference for the hybrid
system in front of the two individual translators.
@InProceedings{enacheEtal12,
author = {{Enache}, R. and {Espa{\~n}a-Bonet}, C. and {Ranta}, A. and {M\`arquez}, L.},
title = {A Hybrid System for Patent Translation},
booktitle = {Proceedings of the 16th Annual Conference of the European Association for Machine Translation (EAMT12)},
pages = {269--276},
year = {2012},
month = {may},
date = {28--30},
address = {Trento, Italy},
language = {english}
}
Context-Aware Machine Translation for Software Localization
Víctor Muntés, Patricia Paladini, Cristina España-Bonet, Lluís Màrquez
Proceedings of the 16th Annual Conference of the European Association for Machine Translation (EAMT12), Trento, Italy, May 8-30, 2012.
[
Abstract
PDF
BibTeX
arXiv
]
Software localization requires translating
short text strings appearing in user interfaces (UI) into several languages. These
strings are usually unrelated to the other
strings in the UI. Due to the lack of semantic context, many ambiguity problems
cannot be solved during translation. However, UI are composed of several visual
components to which text strings are associated. Although this association might
be very valuable for word disambiguation,
it has not been exploited. In this paper,
we present the problem of lack of context awareness for UI localization,
providing real examples and identifying the main
research challenges.
@InProceedings{muntesEtal12,
author = {{Munt\'es}, V. and {Paladini}, P. and {Espa{\~n}a-Bonet}, C. and {M\`arquez}, L.},
title = {Context-Aware Machine Translation for Software Localization},
booktitle = {Proceedings of the 16th Annual Conference of the European Association for Machine Translation (EAMT12)},
pages = {77--80},
year = {2012},
month = {may},
date = {28},
address = {Trento, Italy},
language = {english}
}
Full Machine Translation for Factoid Question Answering
Cristina España-Bonet, Pere R. Comas
Proceedings of the EACL Workshop on Exploiting Synergies between Information Retrieval and Machine Translation (ESIRMT), Avignon, France, April 23, 2012.
[
Abstract
PDF
Slides
BibTeX
arXiv
]
In this paper we present an SMT-based approach to Question Answering (QA). QA
is the task of extracting exact answers in
response to natural language questions. In
our approach, the answer is a translation of
the question obtained with an SMT system.
We use the n-best translations of a given
question to find similar sentences in the
document collection that contain the real
answer. Although it is not the first time that
SMT inspires a QA system, it is the first
approach that uses a full Machine Translation system for generating answers. Our
approach is validated with the datasets of the
TREC QA evaluation.
@InProceedings{espanaComas12,
author = {{Espa{\~n}a-Bonet}, C. and {Comas}, P.R.},
title = {Full Machine Translation for Factoid Question Answering},
booktitle = {Proceedings of the EACL Workshop on Exploiting Synergies between Information Retrieval and Machine Translation (ESIRMT)},
pages = {20--29},
year = {2012},
month = {apr},
date = {23},
address = {Avignon, France},
language = {english}
}
The Patents Retrieval Prototype in the MOLTO project
Milen Chechev, Meritxell Gonzàlez, Lluís Màrquez, Cristina España-Bonet
Proceedings of the World Wide Web 2012, Lyon, France, April 16, 2012.
[
Abstract
PDF
BibTeX
arXiv
]
This paper describes the patents retrieval prototype developed within the MOLTO project. The prototype aims to
provide a multilingual natural language interface for querying the content of patent documents. The developed system
is focused on the biomedical and pharmaceutical domain
and includes the translation of the patent claims and abstracts into English, French and German. Aiming at the
best retrieval results of the patent information and text
content, patent documents are preprocessed and semantically annotated. Then, the annotations are stored and
indexed in an OWLIM semantic repository, which contains a
patent specific ontology and others from the specific domain.
The prototype, accessible online at http://molto-patents.ontotext.com,
presents a multilingual natural language interface to query the retrieval system. In MOLTO, the
multilingualism of the queries is addressed by means of the GF
Tool, which provides an easy way to build and maintain
controlled language grammars for interlingual translation in
limited domains. The abstract representation obtained from
the GF is used to retrieve both the matched RDF1 instances
and the list of patents semantically related to the user's
search criteria. The online interface allows to browse the
retrieved patents and shows on the text the semantic annotations that explain the reason why any particular patent
has matched the user's criteria.
@InProceedings{www12patents,
author = {{Chechev}, M. and {Gonz\`alez}, M. and {M\`arquez}, L. and {Espa{\~n}a-Bonet}, C.},
title = {The Patents Retrieval Prototype in the MOLTO project},
booktitle = {Proceedings of the World Wide Web 2012},
pages = {4-8},
year = {2012},
month = {apr},
date = {16},
address = {Lyon, France},
language = {english}
}
2011
Deep evaluation of hybrid architectures: simple metrics correlated with
human judgments
Gorka Labaka, Arantza Díaz de Ilarraza, Cristina España-Bonet, Lluís Màrquez, Kepa Sarasola
Proceedings of the International Workshop on Using Linguistic Information for Hybrid Machine Translation (LIHMT), Barcelona, November 18th, 2011.
[
Abstract
PDF
Slides
BibTeX
arXiv
]
The process of developing hybrid MT systems
is guided by the evaluation method used to compare different combinations of basic subsystems. This work presents a deep evaluation experiment of a hybrid architecture that tries to get the best of both worlds, rule-based and statistical. In a first evaluation human assessments were used to compare just the single statistical system and the hybrid one, the rule-based system was not compared by hand because the results of automatic evalu ation showed a clear disadvantage. But a second and wider evaluation experiment surprisingly showed that according to human evaluation the best system was the rule-based, the one that achieved the worst results using automatic evaluation. An examination of sentences with controversial results suggested that linguistic well-formedness in the output should be considered in evaluation. After experimenting with 6 possible metrics we conclude that a simple arithmetic mean of BLEU and BLEU calculated on parts of speech of words is clearly a more human conformant metric than lexical metrics alone.
@InProceedings{SMatxinTeval,
author = {{Labaka}, G. and {D\'iaz de Ilarraza}, A. and {Espa{\~n}a-Bonet}, C. and {M\`arquez}, L.
and {Sarasola}, K.},
title = {Deep evaluation of hybrid architectures: simple metrics correlated with human judgments},
booktitle = {Proceedings of the International Workshop on Using Linguistic Information for
Hybrid Machine Translation},
pages = {50-57},
year = {2011},
month = {nov},
date = {19},
address = {Barcelona},
language = {english}
}
Descobrim l'Univers
Cristina España-Bonet
Invited talk at Tertúlies de Literatura Científica, UVic, Vic, October 25th 2011.
[
Abstract
Dossier 1
Dossier 2
Slides
Link video
arXiv
]
En "Descobrim l'Univers" s'han atacat tres aspectes relacionats amb la cosmologia: l'inici de l'Univers, alguns objectes i fenòmens astrofísics, i l'expansió i dimensionalitat de l'Univers. La xerrada es centrarà principalment en aquest últim punt. Partirem de les explicacions amb què us heu pogut familiaritzar amb el dossier subministrat i avançarem cap a entendre el nostre Univers actual, un univers que de manera sorprenent està expandint-se, cada cop es fa més gran, i, a més, ho fa de manera accelerada. L'importància d'aquest descobriment es veu reafirmada pel fet que el premi Nobel de física d'enguany s'ha concedit a tres investigadors que lideren els projectes que ho van anunciar.
Es pot trobar informació addicional al web de les jornades http://tlc.uvic.cat/2011/10/28/activitat-25102011-dra-cristina-espana-upc/.
Patent translation within the MOLTO project
Cristina España-Bonet, Ramona Enache, Adam Slaski, Aarne Ranta,
Lluís Màrquez, Meritxell Gonzàlez
Proceedings of the 4th Workshop on Patent Translation, MT Summit XIII, Xiamen, China, September 23, 2011.
[
Abstract
PDF
Slides
BibTeX
arXiv
]
MOLTO is an FP7 European
project whose goal is to translate texts between multiple
languages in real time with high quality. Patents translation is a case of study where
research is focused on simultaneously obtaining a large coverage without loosing quality
in the translation. This is achieved by hybridising between a grammar-based multilingual
translation system, GF, and a specialised statistical machine translation system.
Moreover, both individual systems by themselves already represent a step forward in the
translation of patents in the biomedical domain, for which the systems have been trained.
@InProceedings{SMatxinT1,
author = {{Espa{\~n}a-Bonet}, C. and {Enache}, R. and {Slaski}, A. and {Ranta}, A.
and {M\`arquez}, L. and {Gonz\`alez}, M.},
title = {Patent translation within the MOLTO project},
booktitle = {Proceedings of the 4th Workshop on Patent Translation, MT Summit XIII},
pages = {70-78},
year = {2011},
month = {sep},
date = {23},
address = {Xiamen, China},
language = {english}
}
Hybrid Machine Translation Guided by a Rule-Based System
Cristina España-Bonet, Gorka Labaka, Arantza Díaz de Ilarraza, Lluís Màrquez, Kepa Sarasola
Proceedings of the 13th Machine Translation Summit, Xiamen, China, September 19-23, 2011.
[
Abstract
PDF
Slides
BibTeX
arXiv
]
This paper presents a machine translation architecture which hybridizes Matxin, a rule-based system, with regular phrase-based Statistical
Machine Translation. In short, the hybrid translation process is guided by the rule-based engine and,
before transference, a set of partial candidate translations provided by SMT subsystems is used to
enrich the tree-based representation. The final hybrid translation is created by choosing the most
probable combination among the available fragments with a statistical decoder in a monotonic way.
We have applied the hybrid model to a pair of distant languages, Spanish and Basque, and according
to our evaluation (both automatic and manual) the hybrid approach significantly outperforms the best SMT system on out-of-domain data.
@InProceedings{SMatxinT1,
author = {{Espa{\~n}a-Bonet}, C. and {Labaka}, G. and {D\'iaz de Ilarraza}, A. and {M\`arquez}, L.
and {Sarasola}, K.},
title = {Hybrid Machine Translation Guided by a Rule-Based System},
booktitle = {Proceedings of the 13th Machine Translation Summit},
pages = {554-561},
year = {2011},
month = {sep},
date = {19-23},
address = {Xiamen, China},
language = {english}
}
Introduction to SMT and its standard tools
Cristina España-Bonet
GF Summer School, Barcelona, August 2011.
[
Abstract
Slides
]
This tutorial is intended to provide an
introduction to Statistical Machine Translation. The statistical paradigm is one of the
predominants within machine translation. This is possibly due to the
simplicity of building a basic system with free software, the large
community behind it and, of course, the good results that it achieves.
The main objective of the session is to get to know the fundamentals
behind the three modules of a statistical system: the language model,
the translation model and the decoding or search for the best
translation. The presentation, although theoretical, is focused on
understanding how software such as SRILM and Moses work, what's the
logic behind them so that it is easy to understand the extensions and modifications available.
We also devote a small portion of time to see how these systems, and
machine translation systems in general, are evaluated automatically.
Machine translation evaluation is a delicate topic. Here we will put
the evaluation into context, describe in detail the standard metrics
and overview on the existing possibilities.
Finally, in a second part, the standard software will be introduced
and if there is time a toy SMT system will be build. Otherwise the
main steps for building it will be given.
2010
El Projecte MOLTO: Multi Lingual On-Line Translation
Cristina España-Bonet
Invited talk at the workshop La Indústria de la Traducció entre Llengües Romàniques, UPV, València, September 2010.
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
L'objectiu final de MOLTO és desenvolupar un conjunt d'eines per a traduir textos entre diversos idiomes en temps real i amb alta qualitat. En aquestes eines cada llengua està pensada com un mòdul independent i, per tant, es pot afegir de manera directa sobre el sistema base. Dintre del projecte es construiran prototips per cobrir la major part dels 23 idiomes oficials a la UE.
Com a tècnica principal, MOLTO utilitza gramàtiques semàntiques de domini específic i interlingues basades en ontologies. Aquests components s'implementen en Grammatical Framework (GF), un formalisme de gramàtiques on es relacionen diversos idiomes a través d'una sintaxi abstracta comuna. El GF s'ha aplicat en diversos dominis de mida petita i mitjana, típicament per tractar fins a un total de deu idiomes, però MOLTO ampliarà això en termes de productivitat i aplicabilitat.
Part de l'ampliació es dedicarà a augmentar la mida dels dominis i el nombre d'idiomes. També és important fer la tecnologia accessible per als experts del domini sense experiència amb GFs i reduir al mínim l'esforç necessari per a la construcció d'un traductor. Idealment, això es pot aconseguir simplement estenent un lexicó i escrivint un conjunt de frases d'exemple.
Per altra banda les parts amb investigació més intensiva de MOLTO són la interoperabilitat entre estàndards d'ontologies (OWL) i les gramàtiques GF, i l'extensió de les traduccions basades en regles amb mètodes estadístics. L'interoperabilitat OWL-GF permetrà la interacció multilingüe basada en llenguatge natural amb coneixement vàlid per a les màquines. Els mètodes estadístics afegiran robustesa al sistema i caldrà desenvolupar nous mètodes per a combinar les gramàtiques GF amb la traducció estadística en benefici de tots dos.
Després dels tres anys que dura el projecte, la tecnologia de MOLTO serà lliurada com a llibreries de codi obert que podran ser connectades a les eines de traducció estàndard i pàgines web i, per tant, podran ser integrades en els fluxos de treball estàndard. En el procés, es crearan demostracions web i la metodologia s'aplicarà a tres estudis de cas: exercicis de matemàtiques en 15 idiomes, dades de patents en almenys 3 idiomes, i descripcions d'objectes de museus en 15 idiomes.
Es pot trobar informació addicional al web oficial http://www.molto-project.eu/.
Robust Estimation of Feature Weights in Statistical Machine Translation
Cristina España-Bonet, Lluís Màrquez
Proceedings of the 14th Annual Conference of the European Association for Machine Translation (EAMT), Saint-Raphaël, France, May 2010.
[
Abstract
Postscript
PDF
Poster
BibTeX
arXiv
]
Weights of the various components in a
standard Statistical Machine Translation model are usually estimated via Minimum Error Rate Training. With this, one finds their optimum value on a development set with the expectation that these optimal weights generalise well to other test sets. However, this is not always the case when domains differ. This work uses a perceptron algorithm to learn more robust weights to be used on out-of-domain corpora without the need for specialised data. For an Arabic-to-English translation system, the generalisation of weights represents an improvement of more than 2 points of BLEU with respect to the MERT baseline using the same information.
@InProceedings{espanaMarquez,
author = {{Espa{\~n}a-Bonet}, C. and {M\`arquez}, L.},
title = {Robust Estimation of Feature Weights in Statistical Machine Translation},
booktitle = {Proceedings of the 14th Annual Conference of the European Association for Machine Translation (EAMT'10)},
year = {2010},
month = {may},
date = {27-28},
address = {Saint-Rapha\"{e}l, France},
language = {english}
}
Language Technology Challenges of a 'small' Language (Catalan)
M. Melero, G. Boleda, M. Cuadros, C. España-Bonet, L. Padró, M. Quixal, C. Rodríguez, R. Saurí
Proceedings of the 7th International Conference on Language Resources and Evaluation (LREC), Valletta, Malta, May 2010.
[
Abstract
Postscript
PDF
Poster
BibTeX
arXiv
]
In this paper, we present a brief snapshot of the state of affairs in computational processing of Catalan and the initiatives that are starting to take place in an effort to bring the field a step forward, by making a better and more efficient use of the already existing resources and tools, by bridging the gap between research and market, and by establishing periodical meeting points for the community. In particular, we present the results of the First Workshop on the Computational Processing of Catalan, which succeeded in putting together a fair representation of the research in the area, and received attention from both the industry and the administration. Aside from facilitating communication among researchers and between developers and users, the Workshop provided the organizers with valuable information about existing resources, tools, developers and providers. This information has allowed us to go a step further by setting up a "harvesting" procedure which will hopefully build the seed of a portal-catalogue-observatory of language resources and technologies in Catalan.
@InProceedings{MELERO10.628,
author = {Maite Melero, Gemma Boleda, Montse Cuadros, Cristina Espa{\~n}a-Bonet, Llu\'is Padr\'o, Mart\'i Quixal,
Carlos Rodr\'iguez and Roser Saur\'i},
title = {Language Technology Challenges of a 'Small' Language (Catalan)},
booktitle = {Proceedings of the Seventh conference on International Language Resources and Evaluation (LREC'10)},
year = {2010},
month = {may},
date = {19-21},
address = {Valletta, Malta},
editor = {Nicoletta Calzolari (Conference Chair), Khalid Choukri, Bente Maegaard, Joseph Mariani, Jan Odjik, Stelios Piperidis,
Mike Rosner, Daniel Tapias},
publisher = {European Language Resources Association (ELRA)},
isbn = {2-9517408-6-7},
language = {english}
}
Statistical Machine Translation - A practical tutorial
Cristina España-Bonet
Tutorial at MOLTO kick-off meeting, Barcelona, March 2010.
[
Abstract
PDF (to show)
PDF (to print)
arXiv
]
Tutorial for beginners in SMT. It is intended
to show the fundamentals in less than 90 minutes and includes some guidelines to construct a SMT
baseline.
Robust Estimation of Feature Weights in SMT
Cristina España-Bonet, Lluís Màrquez
Talk at OpenMT2 kick-off meeting, Ulia, Donostia, January 2010.
[
Abstract
Postscript
PDF
arXiv
]
Weights of the various components in a standard Statistical Machine Translation model are usually estimated via Minimum Error Rate Training. With this, one finds their optimum value on a development set with the expectation that these optimal weights generalise well to other test sets. However, this is not always the case when domains differ. Our work uses a perceptron algorithm to learn more robust weights to be used on out-of-domain corpora without the need for specialised data. For an Arabic-to-English translation system, the generalisation of the weights represents an
improvement of more than 2 points of BLEU with respect to the MERT baseline using exactly the same information.
2009
Discriminative Phrase-Based Models for Arabic Machine Translation
Cristina España-Bonet, Jesús Giménez, Lluís Màrquez
ACM Transactions on Asian Language Information Processing Journal (TALIP), vol. 8, No. 4, pag. 1-20. December, 2009.
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
A design for an Arabic-to-English translation system is presented. The core of the system implements a standard Phrase-Based Statistical Machine Translation architecture, but it is extended by incorporating a local discriminative phrase selection model to address the semantic ambiguity of Arabic. Local classifiers are trained using linguistic information and context to translate a phrase, and this significantly increases the accuracy in phrase selection with respect to the most frequent translation traditionally considered. These classifiers are integrated into the translation system so that the global task gets benefits from the discriminative learning. As a result, we obtain significant improvements in the full translation task at the lexical, syntactic and semantic levels as measured by an heterogeneous set of automatic evaluation metrics.
@article{talip09,
author = {{Espa{\~n}a-Bonet}, C. and {Gim\'enez}, J. and {M\`arquez}, L.},
title = {Discriminative Phrase-Based Models for Arabic Machine Translation},
journal = {ACM Transactions on Asian Language Information Processing Journal (TALIP)},
year = 2010,
month = March,
volume = 8,
issue = 4,
month = December,
year = 2009,
pages = 1--20,
articleno = 15,
doi = {http://doi.acm.org/10.1145/1644879.1644882},
publisher = ACM,
}
CoCo, a web interface for corpora compilation
C. España-Bonet, M. Vila, H. Rodríguez, M.A. Martí
Procesamiento del Lenguaje Natural, 43, 367-368. September, 2009.
[
Abstract
Postscript
PDF
Poster
BibTeX
arXiv
]
CoCo is a collaborative web interface for the compilation of linguistic resources. In this demo we are presenting one of its possible applications: paraphrase acquisition.
@ARTICLE{seplncoco2009,
author = {{Espa{\~n}a-Bonet}, C. and {Vila}, M. and {Mart\'i}. M.A. and {Rodr\'iguez}, H.},
title = {CoCo, a web interface for corpora compilation},
journal = {Procesamiento del Lenguaje Natural},
volume = 43,
pages = {367-368},
year = 2009,
month = September
}
Conclusiones de la primera Jornada del Procesamiento Computacional del Catalán
G. Boleda, M. Cuadros, C. España-Bonet, M. Melero, L. Padró, M. Quixal, C. Rodríguez
Procesamiento del Lenguaje Natural, 43, 387-388. September, 2009.
[
Abstract
Postscript
PDF
Poster
BibTeX
arXiv
]
A partir de la constatación de que la comunidad de investigación de Procesamiento del Lenguaje Natural y del Habla en catalán precisaba mayor cohesión, se organizó una jornada (Jornada del Processament Computacional del Català, JPCC) que se celebró en el Palau Robert de Barcelona en
marzo de 2009. Los objetivos de la jornada eran (1) mejorar la comunicación y la colaboración entre los diferentes grupos de investigación, empresas e instituciones que desarrollan herramientas y recursos computacionales para el catalán, (2) encontrar maneras de aprovechar de forma eficiente los recursos existentes y, (3) dar visibilidad a la investigación en el tratamiento computacional del catalán.
@ARTICLE{seplnjpc2009,
author = {{Boleda}, G. and {Cuadros}, M. and {Espa{\~n}a-Bonet}, C. and {Melero}, M. and {Padr\'o}. L.
and {Quixal}, M. and {Rodr\'iguez}, C.},
title = {Conclusiones de la primera Jornada del Procesamiento Computacional del Catal\'an},
journal = {Procesamiento del Lenguaje Natural},
volume = 43,
pages = {387-388},
year = 2009,
month = September
}
Sobre la I Jornada del Processament Computacional del català
G. Boleda, M. Cuadros, C. España-Bonet, M. Melero, L. Padró, M. Quixal, C. Rodríguez
Llengua i Ús, vol 45, 23-32, 2009.
[
Abstract
Postscript
PDF
BibTeX
arXiv
]
El processament computacional de la llengua abraça qualsevol activitat relacionada amb la creació, gestió i utilització de tecnologia i recursos lingüístics. En el pla científic, aquesta activitat és central en disciplines com ara la lingüística de corpus, l'enginyeria lingüística o el processament del llenguatge natural escrit o parlat. En el pla quotidià, el processament s'inclou en un ampli ventall d'aplicacions cada cop més habituals: sistemes automàtics d'atenció telefònica, traducció automàtica, etc.
La gran majoria d'aquestes aplicacions requereixen eines i recursos lingüístics específics per a cada llengua. Per a llengües amb un mercat ampli, com l'anglès o el castellà, l'oferta de productes i serveis basats en tecnologia lingüística és variada i habitual. Per al cas de llengües com el català, és més difícil trobar productes i serveis que s'ofereixin ja "de fàbrica" amb aquesta tecnologia.
Per tal de reflectir l'estat actual de les tecnologies de la llengua aplicades al català, de posar en contacte els membres d'aquesta comunitat, i d'impulsar iniciatives que les potenciïn, al març del 2009 es va celebrar al Palau Robert de Barcelona la primera Jornada del Processament Computacional del Català. La Jornada tenia l'objectiu d'esdevenir un punt de trobada i alhora un aparador per als grups de recerca de l'àrea, i encetar el debat sobre com articular la comunitat per tal de potenciar l'ús i el desenvolupament del català tant en la tecnologia lingüística com en els productes i serveis que en depenen. Aquest article presenta un resum del contingut i les conclusions de la Jornada.
@ARTICLE{lsc09,
author = {{Boleda}, G. and {Cuadros}, M. and {Espa{\~n}a-Bonet}, C. and {Melero}, M. and {Padr\'o}. L.
and {Quixal}, M. and {Rodr\'iguez}, C.},
title = "Sobre la I Jornada del Processament Computacional del catal\`a",
journal = "Llengua i \'Us",
volume = 45,
pages = 23-32,
year = 2009
}
El català i les tecnologies de la llengua
G. Boleda, M. Cuadros, C. España-Bonet, M. Melero, L. Padró, M. Quixal, C. Rodríguez
Llengua, Societat i Comunicació, vol 7, 20-26, 2009.
[
Abstract
Postscript
PDF
BibTeX
arXiv
]
(See Introduction)
@ARTICLE{lsc09,
author = {{Boleda}, G. and {Cuadros}, M. and {Espa{\~n}a-Bonet}, C. and {Melero}, M. and {Padr\'o}. L.
and {Quixal}, M. and {Rodr\'iguez}, C.},
title = "El catal\`a i les tecnologies de la llengua",
journal = "Llengua, Societat i Comunicaci\'o",
volume = 7,
pages = "20--26",
year = 2009,
month = July
}
Type Ia SNe along redshift: the R(SiII) ratio and the expansion velocities in intermediate z supernovae
G. Altavilla, P. Ruiz-Lapuente, A. Balastegui, J. Mendez, M. Irwin, C. España-Bonet, R.S. Ellis, G. Folatelli, A. Goobar, W. Hillebrandt, R.M. McMahon, S. Nobili, V. Stanishev, N.A. Walton
The Astrophysical Journal, vol 695, 135-148, 2009
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
We present a study of intermediate-z SNe Ia using the empirical physical diagrams which permit the investigation of those SNe explosions. This information can be very useful to reduce systematic uncertainties of the Hubble diagram of SNe Ia up to high z. The study of the expansion velocities and the measurement of the ratio R(SiII) allow subtyping of SNe Ia as done in nearby samples. The evolution of this ratio as seen in the diagram R(SiII)-(t) together with R(SiII)_max versus (B-V)_0 indicates consistency of the properties at intermediate-z compared with the nearby SNe Ia. At intermediate-z, expansion velocities of Ca II and Si II are found similar to those of the nearby sample. This is found in a sample of six SNe Ia in the range 0.033≤z≤0.329 discovered within the International Time Programme of SNe Ia for Cosmology and Physics in the spring run of 2002.The program run under "Omega and Lambda from Supernovae and the Physics of Supernova Explosions" within the International Time Programme at the telescopes of the European Northern Observatory (ENO) at La Palma (Canary Islands, Spain). Two SNe Ia at intermediate-z were of the cool FAINT type, one being an SN1986G-like object highly reddened. The R(SiII) ratio as well as subclassification of the SNe Ia beyond templates help to place SNe Ia in their sequence of brightness and to distinguish between reddened and intrinsically red supernovae. This test can be done with very high z SNe Ia and it will help to reduce systematic uncertainties due to extinction by dust. It should allow to map the high-z sample into the nearby one.
@ARTICLE{midzsne2009,
author = {{Altavilla}, G. and {Ruiz-Lapuente}, P. and {Balastegui}, A. and {Mendez}, J. and {Irwin}, M. and
{Espa{\~n}a-Bonet}, C. and {Ellis}, R.~S. and {Folatelli}, G. and {Goobar}, A. and {Hillebrandt}, W.
and {McMahon}, R.~M. and {Nobili}, S. and {Stanishev}, V. and {Walton}, N.~A.},
title = "{Type Ia SNe along redshift: the R(Si II) ratio and the expansion velocities in intermediate z supernovae}",
journal = {Astrophysical Journal},
eprint = {arXiv:astro-ph/0610143},
year = 2009,
month = april,
volume = 695,
pages = {135-148},
doi = {10.1088/0004-637X/695/1/135},
}
Discriminative learning within Arabic Statistical Machine Translation
Cristina España-Bonet, Jesús Giménez, Lluís Màrquez
Research Report LSI-09-3-R
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
Written Arabic is a especially ambiguous due to the lack of diacritisation of texts, and this makes the translation harder for automatic systems that do not take into account the context of phrases. Here, we use a standard Phrase-Based Statistical Machine Translation architecture to build an Arabic-to-English translation system, but we extend it by incorporating a local discriminative phrase selection model which addresses this semantic ambiguity. Local classifiers are trained using both linguistic information and context to translate a phrase, and this significantly increases the accuracy in phrase selection with respect to the most frequent translation traditionally considered. These classifiers are integrated into the translation system so that the global task gets benefits from the discriminative learning. As a result, we obtain improvements in the full translation of Arabic documents at the lexical, syntactic and semantic levels as measured by an heterogeneous set of automatic metrics.
@TechReport{cespanaLSI093R,
author = {{Espa{\~n}a-Bonet}, C. and {Gim\'enez}, J. and {M\`arquez}, L.},
title = {Discriminative learning within Arabic Statistical Machine Translation},
institution = {LSI, UPC},
year = {2009},
month = {January},
type = {Research Report},
number = {LSI-09-3-R}
}
2008
The UPC-LSI Discriminative Phrase Selection System: NIST MT Evaluation 2008
Cristina España-Bonet, Jesús Giménez, Lluís Màrquez
Proceedings of the 2008 NIST Open Machine Translation Evaluation Workshop
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
This document describes the system developed by the Empirical MT Group at the Technical University of Catalonia, LSI Department, for the Arabic-to-English task at the 2008 NIST MT Evaluation Campaign. Our system explores the application of discriminative learning to the problem of phrase selection in Statistical Machine Translation. Instead of relying on Maximum Likelihood estimates for the construction of translation models, we use local classifiers which
are able to take further advantage of contextual information. Local predictions are softly integrated into a global log-linear phrase-based statistical MT system as an additional feature. Automatic evaluation results according to a heterogeneous set of metrics operating at different linguistic levels are
presented. These show a low level of agreement between metrics. Improvements over the baseline are either inexistent or not significant, except for the case of semantic metrics based on discourse representations and several syntactic metrics based on constituent and dependency parsing.
@InProceedings{,
author = {{Espa{\~n}a-Bonet}, C. and {Gim\'enez}, J. and {M\`arquez}, L.},
title = {The UPC-lsi Discriminative Phrase Selection System: NIST MT Evaluation 2008},
year = {2008},
organization = {NIST Open Machine Translation Evaluation Workshop}
}
A proposal for an Arabic-to-English SMT
Cristina España-Bonet
Master Thesis, Universitat de Barcelona and Universitat Politècnica de Catalunya (Artificial Intelligence Program)
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
Snippet of the Introduction:
The aim of this work is to apply MT techniques to translate from Arabic to English in the context of the 2008 NIST Machine Translation Open evaluation. For the core of the system we choose a SMT architecture. With a standard SMT system we check the improvements given by adding linguistic information, that is,
maximise the probability not only of the sequence of words, but of its lemma, part-of-speech and chunk as well. We increase the amount of linguistic knowledge but we also increase the sparsity in the corpus because the combination of features increases the vocabulary. We explore several approaches to these combinations.
As a second method, we use machine learning (ML) techniques to select the most adequate translation phrases and combine them with the output of the SMT system. We treat the translation task as a classification problem and use the linguistic information and the context of each word as features to train the classifiers. This methodology is used in Word Sense Disambiguation and should help to select the
correct translation of a phrase according to its context. We analyse the results of this subtask and quantify the impact in the results. The output of this phase is inserted into the SMT system by enlarging the translation table with every sense of a phrase and with the inclusion of a new probability score, which accounts for the result of the classifier. We compare the results with and without this additional
information. This combination of SMT and ML, MLT, is our final proposal for the
Arabic-to-English SMT system.
@MastersThesis{crisSMTdea,
author = {{Espa{\~n}a-Bonet}, C.},
title = {A proposal for an Arabic-to-English SMT},
school = {Universitat de Barcelona and Universitat Polit\`ecnica de Catalunya},
year = 2008,
month = February
}
Exploring the evolution of dark energy and its equation of state
Cristina España-Bonet
Ph.D. Thesis, Universitat de Barcelona (Astronomy and Astrophysics Program)
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
Abstract: To be included
@PhdThesis{crisTesi,
author = {{Espa{\~n}a-Bonet}, C.},
title = {Exploring the evolution of dark energy and its equation of state},
school = {Departament d'Astronomia i Meteorologia, Universitat de Barcelona},
year = 2008,
month = February
}
Tracing the equation of state and the density of cosmological constant along z
Cristina España-Bonet, Pilar Ruiz-Lapuente
Journal of Cosmology and Astro-Particle Physics, vol 02, pag 18+, 2008
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
We investigate the equation of state w(z) in a non-parametric form using the latest compilations of the luminosity distance from SNe Ia at high z. We combine the inverse problem approach with a Monte Carlo method to scan the space of priors. In the light of the latest high redshift supernova data sets, we reconstruct w(z). A comparison between a sample including the latest results at z>1 and a sample without those results shows the improvement achieved through observations of very high z supernovae. We present the prospects for measuring the variation of dark energy density along z by this method.
@ARTICLE{2008JCAP...02..018E,
author = {{Espa{\~n}a-Bonet}, C. and {Ruiz-Lapuente}, P.},
title = "{Tracing the equation of state and the density of the cosmological constant along z}",
journal = {Journal of Cosmology and Astro-Particle Physics},
archivePrefix = "arXiv",
eprint = {0805.1929},
year = 2008,
month = feb,
volume = 2,
pages = {18-+},
doi = {10.1088/1475-7516/2008/02/018},
adsurl = {http://adsabs.harvard.edu/abs/2008JCAP...02..018E},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
2006
Type Ia SNe along redshift: the R(Si II) ratio and the expansion velocities in intermediate z supernovae
G. Altavilla, P. Ruiz-Lapuente, A. Balastegui, J. Mendez, M. Irwin, C. España-Bonet, K. Schamaneche, C. Balland, R.S. Ellis, S. Fabbro, G. Folatelli, A. Goobar, W. Hillebrandt, R.M. McMahon, M. Mouchet, A. Mourao, S. Nobili, R. Pain, V. Stanishev, N.A. Walton
Submitted to The Astrophysical Journal
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
We study intermediate-z SNe Ia using the empirical physical diagrams which enable to learn about those SNe explosions. This information can be very useful to reduce systematic uncertainties of the Hubble diagram of SNe Ia up to high z. The study of the expansion velocities and the measurement of the ratio R(SiII) allow to subtype those SNe Ia as done for nearby samples. The evolution of this ratio as seen in the diagram R(SiII)-(t) together with R(SiII)_max versus (B-V)_0 indicate consistency of the properties at intermediate z compared with local SNe. At intermediate-z, the expansion velocities of Ca II and Si II are similar to the nearby counterparts. This is found in a sample of 6 SNe Ia in the range 0.033≤z≤0.329 discovered within the International Time Programme (ITP) of Cosmology and Physics with SNe Ia during the spring of 2002. Those supernovae were identified using the 4.2m William Herschel Telescope. Two SNe Ia at intermediate z were of the cool FAINT type, one being a SN1986G-like object highly reddened. The R(SiII) ratio as well as subclassification of the SNe Ia beyond templates help to place SNe Ia in their sequence of brightness and to distinguish between reddened and intrinsically red supernovae. This test can be done with very high z SNe Ia and it will help to reduce systematic uncertainties due to extinction by dust. It should allow to map the high-z sample into the nearby one.
@ARTICLE{2006astro.ph.10143A,
author = {{Altavilla}, G. and {Ruiz-Lapuente}, P. and {Balastegui}, A. and {Mendez}, J. and {Irwin}, M. and
{Espa{\~n}a-Bonet}, C. and {Schamaneche}, K. and {Balland}, C. and {Ellis}, R.~S. and {Fabbro}, S. and
{Folatelli}, G. and {Goobar}, A. and {Hillebrandt}, W. and {McMahon}, R.~M. and {Mouchet}, M. and
{Mourao}, A. and {Nobili}, S. and {Pain}, R. and {Stanishev}, V. and {Walton}, N.~A.},
title = "{Type Ia SNe along redshift: the R(Si II) ratio and the expansion velocities in intermediate z supernovae}",
journal = {ArXiv Astrophysics e-prints},
eprint = {arXiv:astro-ph/0610143},
keywords = {Astrophysics},
year = 2006,
month = oct,
adsurl = {http://adsabs.harvard.edu/abs/2006astro.ph.10143A},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
2004
Dark Energy as an Inverse Problem
Cristina España-Bonet, Pilar Ruiz-Lapuente
Poster at JENAM The many scales in the Universe, IAA, Granada, September 2004
[
Abstract
Postcript
JPG
Slides
BibTeX
arXiv
]
In order to improve the information on dark energy it is not only important
to have a large number of data of a good quality, but also to know where are
these data more profitable and then explode all the statistical methods to
extract the information. We apply here the Inverse Problem Theory to
determine the parameters appearing in the equation of state and the
functional form itself. Using this method it is also determined which would
be the best distribution of high redshift data to study the equation of state
of dark energy, i.e., with which distribution it is obtained a best quality
of the inversion. Supernovae magnitudes are used alone and together with
other sources such as radio galaxies and compact radio sources.
Viabilitat d'una Constant Cosmològica variable. Contrast amb SNeIa.
Cristina España-Bonet
Master Thesis (DEA), Universitat de Barcelona (Astronomy and Astrophysics Program)
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
En aquest treball s'analitza detalladament el comportament de la constant
cosmològica des del punt de vista d'una teoria quàntica de camps. Un cop
obtinguda l'evolució que experimenta a baixes energies, aquesta ens ha permès
comparar les prediccions del model amb altres formes d'energia fosca, amb
les SNeIa a alt redshift com a eina per a fer aquesta comparació.
A partir del canvi de la seva magnitud amb el redshift s'ha comprovat
que aquesta família de models és perfectament compatible amb les observacions
i, per tant, no es pot descartar la possibilitat de que la constant
cosmològica evolucioni amb el temps. La consideració de diferents escenaris
ha permès ajustar paràmetres com la massa dels neutrins lleugers
(mν~ 0,01eV), contrastar la compatibilitat del model estàndard
de partícules amb dades astrofísiques, i determinar paràmetres
relacionats amb la física que es pugui
donar a l'època de Planck. A banda dels resultats que es troben amb les dades
actuals, diverses simulacions de conjunts de dades futures com les del
projecte SNAP han ajudat a veure la contrastabilitat del model. Així, els
projectes planejats per a obtenir SNeIa a alt redshift per a l'estudi
de l'energia fosca seran suficients, en la major part dels casos, per a
verificar o no l'evolució de la constant cosmològica.
@MastersThesis{crisAstroDEA,
author = {{Espa{\~n}a-Bonet}, C.},
title = {Viabilitat d'una Constant Cosmològica variable. Contrast amb SNeIa.},
school = {Dept. Astronomia i Meteorologia, Universitat de Barcelona},
year = 2004,
month = September
}
Testing the running of the cosmological constant with Type Ia Supernovae at high z
Cristina España-Bonet, Pilar Ruiz-Lapuente, Ilya L. Shapiro, Joan Solà
Journal of Cosmology and Astro-Particle Physics, vol 02, pag 6+, 2004
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
Within the Quantum Field Theory context the idea of a cosmological constant (CC) evolving with time looks quite natural as it just reflects the change of the vacuum energy with the typical energy of the universe. In the particular frame of Ref.[30], a running CC at low energies may arise from generic quantum effects near the Planck scale, MP , provided there is a smooth decoupling of all massive particles below MP . In this work we further develop the cosmological consequences of a running CC by addressing the accelerated evolution of the universe within that model. The rate of change of the CC stays slow, without fine-tuning, and is comparable to H2 MP2. It can be described by a single parameter, ν, that can be determined from already planned experiments using SNe Ia at high z. The range of allowed values for ν follow mainly from nucleosynthesis restrictions. Present samples of SNe Ia can not yet distinguish between a constant CC or a running one. The numerical simulations presented in this work show that SNAP can probe the predicted variation of the CC either ruling out this idea or confirming the evolution hereafter expected.
@ARTICLE{2004JCAP...02..006E,
author = {{Espa{\~n}a-Bonet}, C. and {Ruiz-Lapuente}, P. and {Shapiro}, I.~L. and {Sol{\`a}}, J.},
title = "{Testing the running of the cosmological constant with type Ia supernovae at high z}",
journal = {Journal of Cosmology and Astro-Particle Physics},
eprint = {arXiv:hep-ph/0311171},
year = 2004,
month = feb,
volume = 2,
pages = {6-+},
adsurl = {http://adsabs.harvard.edu/abs/2004JCAP...02..006E},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
2003
Variable Cosmological Constant as a Planck scale effect
Ilya L. Shapiro, Joan Solà, Cristina España-Bonet, Pilar Ruiz-Lapuente
Physics Letters B, 574, pag 149-155, 2003
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
We construct a semiclassical FLRW cosmological model assuming a running cosmological constant (CC). It turns out that the CC becomes variable at arbitrarily low energies due to the remnant quantum effects of the heaviest particles, e.g. the Planck scale physics. These effects are universal in the sense that they lead to a low-energy structure common to a large class of high-energy theories. Remarkably, the uncertainty concerning the unknown high-energy dynamics is accumulated into a single parameter ν, such that the model has an essential predictive power. Future Type Ia supernovae experiments (like SNAP) can verify whether this framework is correct. For the flat FLRW case and a moderate value ν~0.01, we predict an increase of 10-20% in the value of ΩΛ at redshifts z=1-1.5 perfectly reachable by SNAP.
@ARTICLE{2003PhLB..574..149S,
author = {{Shapiro}, I.~L. and {Sol{\`a}}, J. and {Espa{\~n}a-Bonet}, C. and {Ruiz-Lapuente}, P.},
title = "{Variable cosmological constant as a Planck scale effect}",
journal = {Physics Letters B},
eprint = {arXiv:astro-ph/0303306},
year = 2003,
month = nov,
volume = 574,
pages = {149-155},
doi = {10.1016/S0370-2693(03)01376-5},
adsurl = {http://adsabs.harvard.edu/abs/2003PhLB..574..149S},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
Supernovae and Cosmology
Cristina España-Bonet
Talk given at Dpt. Estructura i Constituents de la Matèria (Universitat de Barcelona), Dpt. Física i Enginyeria Nuclear (Universitat Politècnica de Catalunya) and Institut de Física d'Altes Energies.
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
Les supernoves tipus Ia (SNe Ia) són les úniques candeles estàndard
que es coneixen a alts redshifts. Això fa que s'haguin convertit en
una de les principals eines per la cosmologia. Aquí s'explicarà com
la determinació de la seva distància lluminositat permet discriminar
entre diferents models cosmològics (amb principal atenció a com s'ha
arribat a la conclusió més acceptada que vivim en un univers en
expansió accelerada dominat per la constant cosmològica) i en quin
estat es troben actualment les investigacions.
2002
Present-day running of the cosmological constant
Cristina España-Bonet, Pilar Ruiz-Lapuente
Poster at the Winter School Dark matter and dark energy in the Universe, IAC, Tenerife, November 2002
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
A particle physics account of the cosmological constant is given through two
different approaches. Both of them use the equations of quantum field theory
and so the cosmological "constant" has its own renormalization group
equation (RGE). The obtained running is then introduced into the theoretical
expression for the magnitude-redshift relation, so that a minimization of
the residuals with the observational data from supernovae (SN) allows us to
fit some parameters. Among the latter are the lightest neutrino masses, for
which the best value is mν = 0.004-0.005 eV (with the possible
presence of a sterile light field). Future applications of the type of
analysis presented here are finally pointed out.
Present-day running of the cosmological constant
Cristina España-Bonet, Pilar Ruiz-Lapuente
Proceedings from On the nature of dark energy, IAP, Paris, July 2002
[
Abstract
Postscript
PDF
Slides
BibTeX
arXiv
]
A particle physics account of the cosmological constant is given through two
different approaches. Both of them use the equations of quantum field theory
and so the cosmological "constant" has its own renormalization group
equation (RGE). The obtained running is then introduced into the theoretical
expression for the magnitude-redshift relation, so that a minimization of
the residuals with the observational data from supernovae (SN) allows us to
fit some parameters. Among the latter are the lightest neutrino masses, for
which the best value is mν = 0.004-0.005 eV (with the possible
presence of a sterile light field). Future applications of the type of
analysis presented here are finally pointed out.





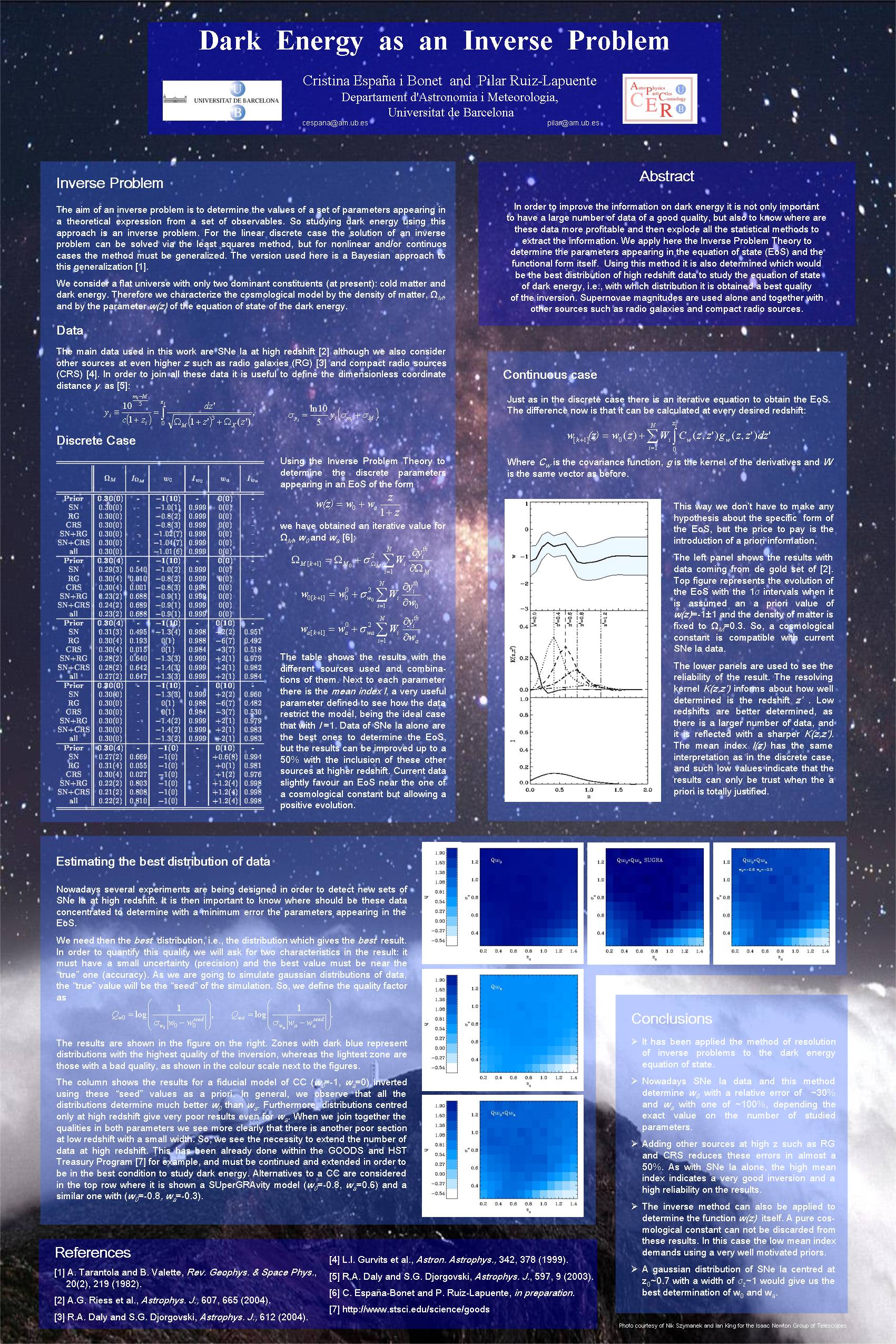{kind=link}